
In today’s data-driven world, building real-time pipelines is a key skill for engineers and data scientists alike. In this tutorial, we will create a simple yet powerful real-time data pipeline that consumes live edit events from Wikimedia, pushes them into Apache Kafka, and then reads them from Kafka to store in OpenSearch.
Whether you’re building analytics dashboards, monitoring systems, or enriching search indexes, this setup is a great foundation. Let’s dive in!
Project Overview
Here’s what we’ll build:
- A Python producer that:
- Connects to the Wikimedia Recent Changes stream
- Sends each event into a Kafka topic
- A Python consumer that:
- Reads messages from the Kafka topic
- Parses and sends them into an OpenSearch index
Source code:
https://github.com/mjmichael73/python-wikimedia-kafka-opensearch
Prerequisites
We’ll assume you already have:
✅ A running Kafka cluster – local using docker compose or remote
✅ A running OpenSearch cluster – local using docker compose or remote
✅ Python 3.8+ installed
✅ Docker and Docker compose installed
✅ Kafka topic named wikimedia.recentchange created
Project Structure:
Step 1:
create a project folder wherever you want on your local computer.
we name it “python-wikimedia-kafka-opensearch”.
Step 2:
create a folder named “producer” and another folder named “consumer” inside the project root.
Step 3:
create a docker compose file named “docker-compose.yml” in project root with this content:
services:
producer-app:
build:
context: ./producer
dockerfile: Dockerfile
container_name: producer-app
volumes:
- ./producer:/app
depends_on:
- broker
networks:
- pwko-net
consumer-app:
build:
context: ./consumer
dockerfile: Dockerfile
container_name: consumer-app
volumes:
- ./consumer:/app
depends_on:
- broker
networks:
- pwko-net
broker:
image: apache/kafka:latest
container_name: broker
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_LISTENERS: PLAINTEXT://broker:9092,CONTROLLER://broker:9093
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@broker:9093
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_NUM_PARTITIONS: 3
networks:
- pwko-net
opensearch-node1:
image: opensearchproject/opensearch:latest
container_name: opensearch-node1
environment:
- cluster.name=opensearch-cluster
- node.name=opensearch-node1
- discovery.seed_hosts=opensearch-node1,opensearch-node2
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- plugins.security.disabled=true
- DISABLE_INSTALL_DEMO_CONFIG=true
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- opensearch-data1:/usr/share/opensearch/data
ports:
- 9200:9200
- 9600:9600
networks:
- pwko-net
opensearch-node2:
image: opensearchproject/opensearch:latest
container_name: opensearch-node2
environment:
- cluster.name=opensearch-cluster
- node.name=opensearch-node2
- discovery.seed_hosts=opensearch-node1,opensearch-node2
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- plugins.security.disabled=true
- DISABLE_INSTALL_DEMO_CONFIG=true
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- opensearch-data2:/usr/share/opensearch/data
networks:
- pwko-net
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:latest
container_name: opensearch-dashboards
ports:
- 5601:5601
expose:
- "5601"
environment:
OPENSEARCH_HOSTS: '["http://opensearch-node1:9200","http://opensearch-node2:9200"]'
DISABLE_SECURITY_DASHBOARDS_PLUGIN: "true"
networks:
- pwko-net
volumes:
opensearch-data1:
opensearch-data2:
networks:
pwko-net:
driver: bridge
This file includes OpenSearch and Kafka broker with “producer-app” and “consumer-app”.
Step 4:
Create a Dockerfile inside “producer” folder named “Dockerfile”:
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["python", "main.py"]
This is necessary for docker compose to work, as we are dockerizing the project.
Step 5:
Create a requirements.txt file inside “producer” folder with this content:
kafka-python
requests
sseclient-pyThese are necessary libraries to work with Kafka and OpenSearch and also getting stream of data from Wikimedia.
Step 6:
Now create a file named “main.py” inside “producer” folder with this content:
import json
import requests
from sseclient import SSEClient
from kafka import KafkaProducer
import time
WIKIMEDIA_STREAM_URL = "https://stream.wikimedia.org/v2/stream/recentchange"
KAFKA_TOPIC = "wikimedia.recentchange"
KAFKA_BROKERS = ["broker:9092"]
def create_producer():
for _ in range(10):
try:
return KafkaProducer(
bootstrap_servers=KAFKA_BROKERS,
value_serializer=lambda v: json.dumps(v).encode("utf-8"),
)
except Exception:
print("Kafka broker not available, retrying...")
time.sleep(5)
def main():
print("Starting Wikimedia Kafka Producer...")
producer = create_producer()
response = requests.get(WIKIMEDIA_STREAM_URL, stream=True)
client = SSEClient(response)
for event in client.events():
if event.event == "message":
try:
data = json.loads(event.data)
producer.send(KAFKA_TOPIC, value=data)
print(f"Produced event to KAFKA: {data.get('title')}")
except Exception as e:
print(f"Error parsing event: {e}")
if __name__ == "__main__":
main()As you can see after importing necessary libraries, we are creating two functions named “create_producer” and “main”, The first one is to create a producer and its repeatedly trying to create a Kafka Producer, This is because when we are using Docker it takes some time for the Kafka broker to gets up and running and we are handling this using retry mechanism.
The main function, creates a “producer” object using “create_producer” function and then requests to WikiMedia to get its stream of data using SSEClient.
Now we are done with “producer” folder.
Let’s go to implementation of the “consumer” folder.
Step 7:
Create a Dockerfile inside “consumer” folder with this content:
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["python", "main.py"]
Step 8:
Create a “requirements.txt” file inside “consumer” folder with this content:
kafka-python
requests
opensearch-pyAs you can see we are using kafka-python library to connect to Apache Kafka container and we are using opensearch-py to connect to OpenSearch container.
Step 9:
Create a main.py file inside “consumer” folder with this content:
import json
import time
from kafka import KafkaConsumer
from opensearchpy import OpenSearch
KAFKA_TOPIC = "wikimedia.recentchange"
KAFKA_BROKERS = "broker:9092"
OPENSEARCH_HOST = "opensearch-node1"
OPENSEARCH_INDEX = "wikimedia-changes"
def create_consumer():
for _ in range(10):
try:
return KafkaConsumer(
KAFKA_TOPIC,
bootstrap_servers=KAFKA_BROKERS,
value_deserializer=lambda m: json.loads(m.decode("utf-8")),
auto_offset_reset="latest",
group_id="wikimedia-consumer-group",
)
except Exception:
print("Kafka broker not available, retrying...")
time.sleep(5)
def connect_opensearch():
for _ in range(20):
try:
print("Trying to connect to OpenSearch...")
client = OpenSearch(
hosts=[{"host": OPENSEARCH_HOST, "port": 9200}],
use_ssl=False,
verify_certs=False,
scheme="http",
)
if not client.indices.exists(index=OPENSEARCH_INDEX):
client.indices.create(index=OPENSEARCH_INDEX)
print(f"Index {OPENSEARCH_INDEX} created.")
return client
except Exception as e:
print(f"OpenSearch not available, retrying... {e}")
time.sleep(5)
raise Exception("OpenSearch connection failed after multiple attempts.")
def main():
print("Starting Kafka Consumer...")
consumer = create_consumer()
os_client = connect_opensearch()
for message in consumer:
try:
doc = message.value
doc_id = doc.get("id")
os_client.index(
index=OPENSEARCH_INDEX,
id=doc_id,
body=doc,
)
print(f"Indexed document with ID: {doc_id}")
except Exception as e:
print(f"Error indexing document: {e}")
continue
if __name__ == "__main__":
main()
We are creating three functions named “connent_consumer” and “connect_opensearch” and “main”.
The first one is for creating a consumer object with retry mechanism as I described for creating a producer above.
The second one is to create a OpenSearch client object, also with retry mechanism, as I described it takes some time for containers to get up and running.
The main function first creates two clients one named “consumer” which is our Kafka Consumer object and the second one is our OpenSearch object.
Then in the main function we do a for loop and try to send messages to OpenSearch Indexing Database.
Now the project is complete, Let’s test it.
Step 10:
To test the project, just run this command:
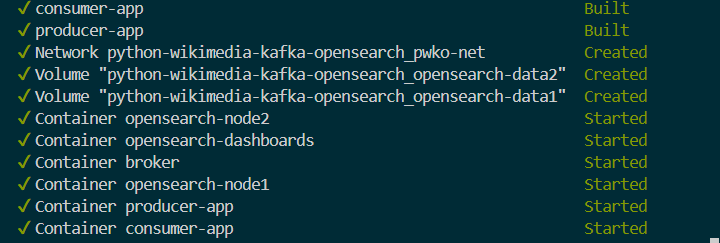
docker compose up --build -d
After doing this containers get up and running as you can see in the image below:
Now lets run this command:
docker compose ps

As you can see all the containers are up and running.
Now lets see the logs of “producer-app” container by running this command:
docker compose logs -f producer-app
Here is the results:
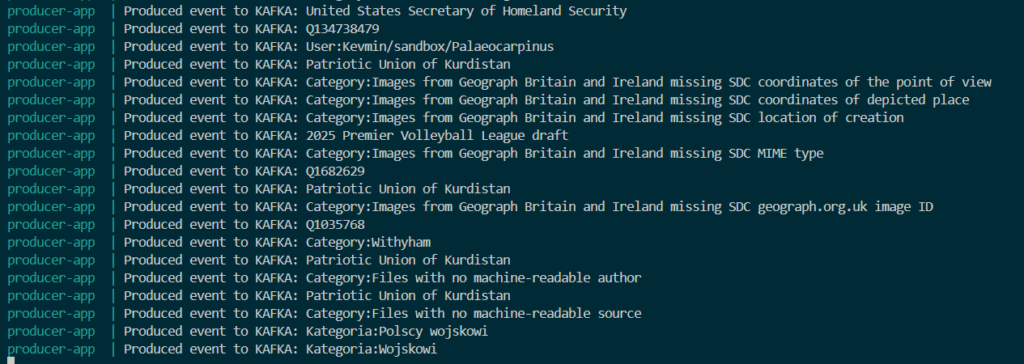
As you can see it’s getting streams from Wikimedia and then sending them as events to Apache Kafka.
Now let’s look at “consumer-app” by running this command:
docker compose logs -f consumer-app
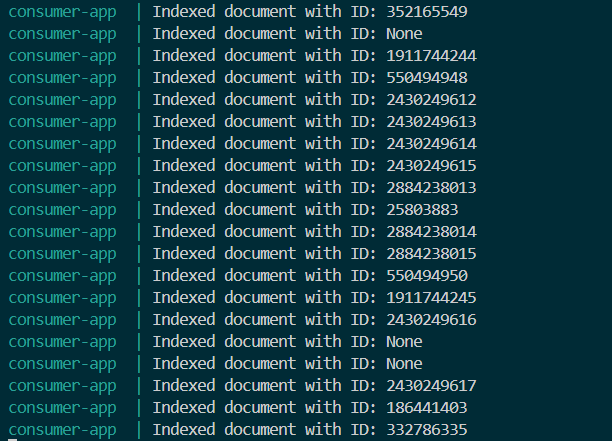
As you can see it’s endlessly receiving events from the broker and sending them to OpenSearch Indexing database container.
Now let’s query something in OpenSearch Indexing database to see if the data is indexed or not.
To do this we will use OpenSearchDashboard container which we have in our docker compose file, to access it go to this address:
http://localhost:5601
After opening this URL open the left side menu and go to Management section as below:
Click on DevTools and You will see something like this:
In the left panel write something like this:
GET /wikimedia-changes
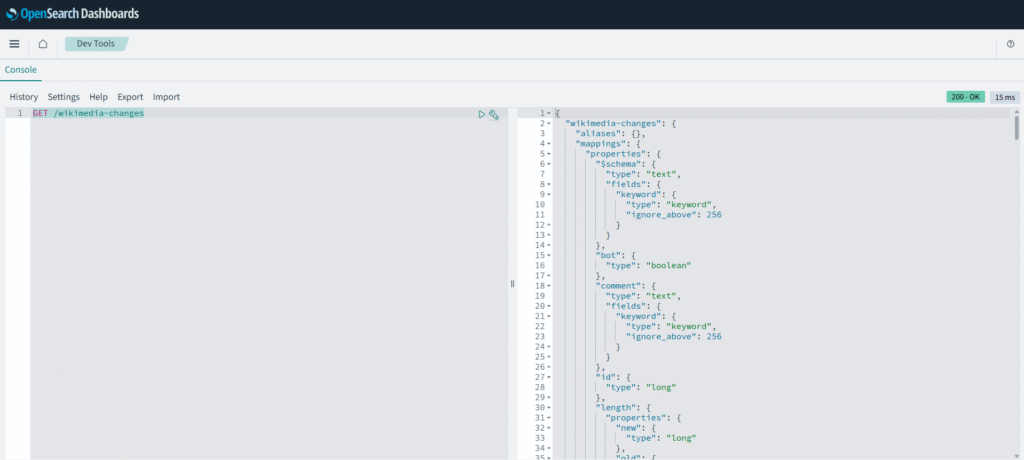
And as you can see everything is working fine.
Hooray !
The source code of project is available at:
https://github.com/mjmichael73/python-wikimedia-kafka-opensearch
Leave a Reply