Go’s concurrency story is famously simple on the surface—spawn goroutines, coordinate with channels, and let the runtime handle the rest. Under the hood, though, the Golang scheduler is a sophisticated piece of engineering that multiplexes thousands (or millions) of goroutines onto a smaller pool of OS threads, balancing throughput, latency, fairness, and interaction with the garbage collector (GC).
If you’ve ever wondered why a Go program scales well on multi-core machines, why GOMAXPROCS matters, or why one blocking call can stall a whole pipeline, this article explains the scheduler in detail—without losing sight of what you need to write fast, reliable, production-grade systems.
Table of Contents
- What the Golang Scheduler Does (and Why It Exists)
- Key Concepts: Goroutines vs OS Threads
- The G-M-P Model Explained
- Goroutine States and Lifecycle
- Run Queues: Local and Global
- Work Stealing: How Go Balances Load
- Syscalls, Blocking, and Thread Parking
- Network Poller (netpoller): Why I/O Scales
- Preemption and Fairness (Go 1.14+)
- Scheduler and Garbage Collection (GC) Interaction
- Tuning Knobs: GOMAXPROCS, CPU Limits, and Containers
- Common Performance Pitfalls (and Fixes)
- Observability: Tracing and Debugging the Scheduler
- Practical Tips for Scheduler-Friendly Go Code
- FAQ
- Conclusion
What the Golang Scheduler Does (and Why It Exists)
The Go runtime scheduler is responsible for deciding:
- Which goroutine runs next
- On which OS thread
- On which CPU core
- How to keep CPUs busy while keeping latency reasonable
Instead of binding a goroutine to a dedicated OS thread (which is expensive), Go uses an M:N scheduling model:
- M goroutines run on
- N OS threads (typically far fewer)
This makes goroutines lightweight (small initial stacks, cheap creation) and makes it feasible to express concurrency at a high level.
Key Concepts: Goroutines vs OS Threads
OS threads
- Managed by the operating system kernel
- Larger memory overhead (stack, kernel structures)
- More expensive context switches
Goroutines
- Managed by the Go runtime
- Small initial stack (grows/shrinks)
- Very cheap to create and schedule compared to threads
The scheduler’s job is to map many goroutines onto a manageable number of threads while keeping the program responsive and efficient.
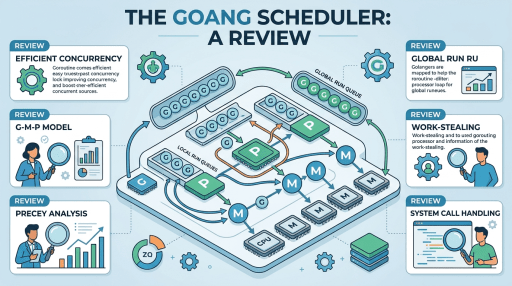
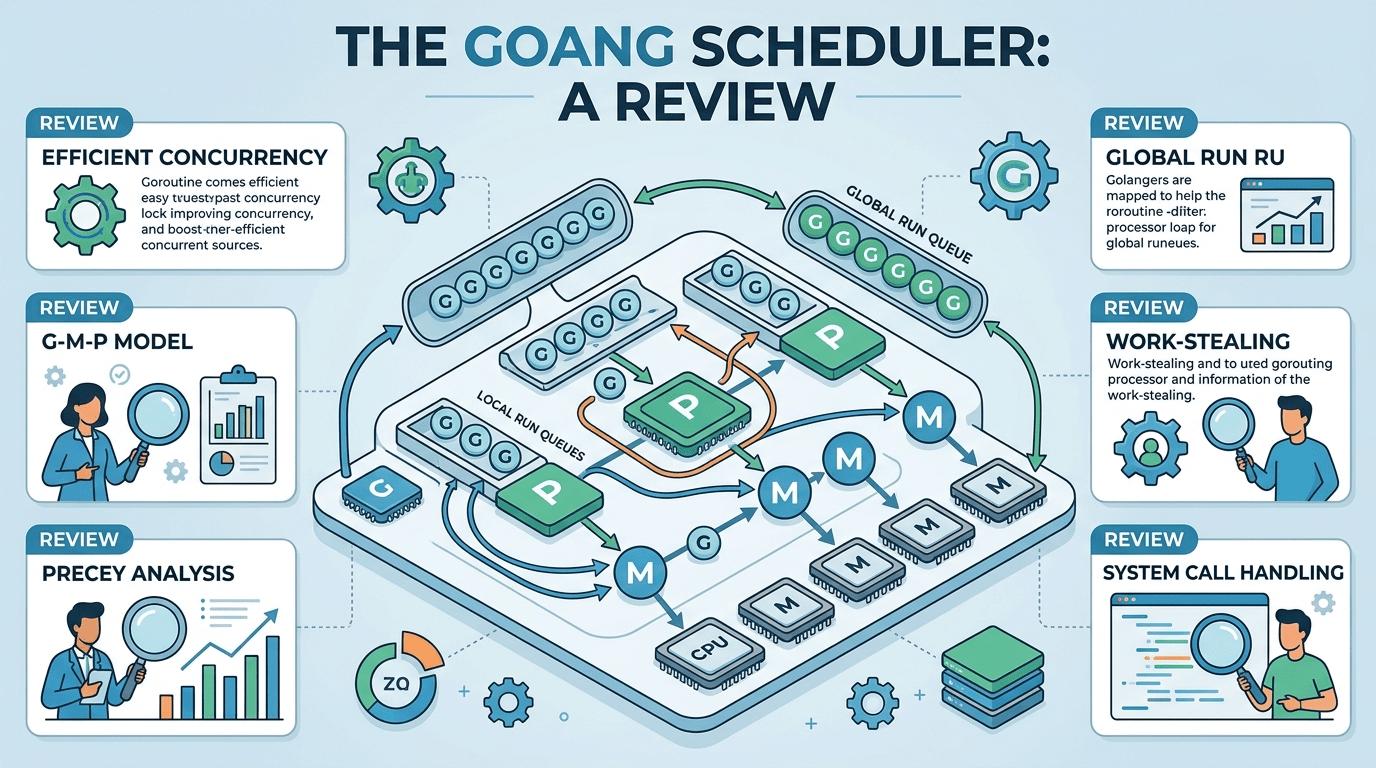
The G-M-P Model Explained
Go’s scheduler is commonly described using the G-M-P model:
- G (Goroutine): the unit of work (your function running concurrently)
- M (Machine): an OS thread executing Go code
- P (Processor): a logical processor that holds scheduler state and run queues
A helpful mental model:
- An M runs Go code only when it has a P
- A P is like a “token” that grants an OS thread the right to execute Go goroutines
- The number of Ps equals
GOMAXPROCS(by default, usually the number of CPU cores available)
Why introduce P at all?
Because it reduces contention. Each P has its own local run queue, allowing most scheduling operations to occur without global locks.
Rule of thumb:
- More Ps means more parallelism (up to CPU availability)
- Too many active goroutines can still cause overhead; the scheduler isn’t magic—it’s a tradeoff engine.
Goroutine States and Lifecycle
A goroutine typically moves through states like:
- Runnable: ready to run, waiting in a run queue
- Running: currently executing on an M with a P
- Waiting: blocked on I/O, channel ops, mutex, sleep, syscall, etc.
- Dead: finished execution
Transitions happen constantly. For example:
- A goroutine doing
<-chmay become waiting - When another goroutine sends on
ch, the receiver becomes runnable - The scheduler places it on a run queue to execute soon
Understanding these transitions is key when diagnosing stalls and throughput issues.
Run Queues: Local and Global
Go maintains two main kinds of runnable queues:
1) Local run queue (per-P)
Each P has a local queue of runnable goroutines. Most scheduling happens here because it’s fast and lock-light.
2) Global run queue
When goroutines are made runnable in certain situations (or when local queues overflow), they may be placed in a global queue. Ps pull from the global queue periodically to ensure fairness.
Why does this matter?
If one P’s local queue gets very hot while others are idle, Go relies on work stealing (covered next) and periodic global checks to rebalance.
Work Stealing: How Go Balances Load
Work stealing is the mechanism that keeps CPUs busy when some Ps run out of work.
When a P’s local queue is empty:
- It checks the global run queue.
- If still empty, it attempts to steal runnable goroutines from another P’s local queue (typically taking about half of them).
- If there’s truly no work, the M may park (sleep) until work appears.
Work stealing improves throughput and reduces the chance that one CPU sits idle while another is overloaded.
Syscalls, Blocking, and Thread Parking
Blocking is where scheduler design becomes very visible.
Blocking in pure Go (channels, mutexes)
If a goroutine blocks on a channel or mutex, the scheduler can usually park that goroutine and run another on the same M/P without involving the OS.
Blocking in syscalls
Syscalls are trickier. If a goroutine enters a blocking syscall (like a file read on some platforms/filesystems), the OS thread (M) may block in the kernel.
To avoid losing parallelism:
- The runtime can detach the P from the blocked M
- It can then attach that P to another M (another thread) so other goroutines can keep running
This is a big reason Go handles many concurrent operations without requiring you to manage thread pools manually.
cgo note
Calls into C via cgo may behave differently and often tie up an OS thread longer. In cgo-heavy programs, you may see more threads and different scheduling behavior.
Network Poller (netpoller): Why I/O Scales
Go’s networking performance depends heavily on the netpoller, an event-driven subsystem built on platform primitives like:
epoll(Linux)kqueue(BSD/macOS)- IOCP (Windows)
Instead of blocking an OS thread per network connection, Go can:
- Park the goroutine waiting on network I/O
- Use the netpoller to wake it when the socket is ready
- Make it runnable again without dedicating a thread to each connection
This design is one reason Go is popular for high-concurrency servers: many connections can be handled with relatively few threads.
Preemption and Fairness (Go 1.14+)
Historically, Go scheduling relied heavily on cooperative preemption at safe points (function calls, channel ops, allocations). That meant a goroutine in a tight CPU loop could starve others.
Asynchronous preemption (Go 1.14 and later)
Modern Go includes improved asynchronous preemption, allowing the runtime to interrupt long-running goroutines more effectively, improving:
- Latency (other goroutines get time sooner)
- Fairness (less starvation)
- Responsiveness under CPU-heavy workloads
Still, tight loops can be problematic
Even with better preemption, you should avoid writing “busy loops” that do no blocking and no calls. If you must poll, consider:
time.Sleep(...)- blocking on a channel
runtime.Gosched()(rarely the best fix, but useful in special cases)
Scheduler and Garbage Collection (GC) Interaction
Go uses a concurrent garbage collector, but GC still affects scheduling.
Key points:
- During certain phases, the runtime may require goroutines to reach safe points.
- The GC may use assist mechanisms where running goroutines help perform GC work proportional to allocations.
- The scheduler must balance running application goroutines with GC workers.
What this means for performance
- High allocation rates can increase GC pressure and influence scheduling.
- Reducing allocations often improves not just memory usage but also CPU time and scheduler behavior.
Tuning Knobs: GOMAXPROCS, CPU Limits, and Containers
GOMAXPROCS
GOMAXPROCS controls the number of Ps (logical processors) available to run Go code simultaneously.
- Default: typically the number of CPU cores available
- Set via:
runtime.GOMAXPROCS(n)- environment variable:
GOMAXPROCS=n
Containers and CPU quotas
In containers (Docker/Kubernetes), CPU limits/quotas can confuse naive CPU detection. Modern Go versions generally handle cgroup limits better than older versions, but it’s still important to validate.
Practical advice:
- For CPU-bound services, ensure
GOMAXPROCSroughly matches CPU limit. - For latency-sensitive services, test different values; max throughput isn’t always best tail latency.
Common Performance Pitfalls (and Fixes)
1) Spawning unbounded goroutines
Problem: Creating a goroutine per request/event with no backpressure can explode memory and increase scheduling overhead.
Fix: Use worker pools or semaphores.
var sem = make(chan struct{}, 100) // limit concurrency
func handle(item Item) {
sem <- struct{}{}
go func() {
defer func() { <-sem }()
process(item)
}()
}2) Hot locks and high contention
Problem: Many goroutines fighting over a mutex leads to context switching and poor scaling.
Fixes:
- Reduce shared state
- Shard locks (striping)
- Use channels or lock-free patterns carefully
- Use
sync.RWMutexwhen reads dominate (measure first)
3) Busy-wait loops
Problem: A goroutine spins on a condition, consuming CPU and harming fairness.
Fix: Block on a channel/condvar, or sleep briefly.
4) Blocking I/O where you expect non-blocking
Problem: Certain file I/O patterns may block OS threads.
Fix: Consider async designs, dedicated goroutines for blocking operations, or measure thread growth under load.
5) Excessive timers
Problem: Massive numbers of timers (time.After in tight loops) can create overhead.
Fix: Reuse timers (time.NewTimer + Reset), or use tickers appropriately.
Observability: Tracing and Debugging the Scheduler
When performance questions arise, don’t guess—measure.
1) Runtime tracing (runtime/trace)
Captures scheduler events, goroutine lifecycles, syscalls, network blocking, GC, and more.
f, _ := os.Create("trace.out")
defer f.Close()
trace.Start(f)
defer trace.Stop()
// run workload hereThen inspect:
go tool trace trace.outThis is one of the best ways to see scheduling delays, goroutine contention, and blocking.
2) Profiling (pprof)
CPU profiles can reveal time spent in scheduling, locking, syscalls, and GC.
go tool pprof- net/http/pprof endpoints in services
3) Scheduler debug output (GODEBUG)
The runtime exposes scheduler diagnostics via GODEBUG.
Common flags:
schedtrace=1000(print scheduler summary every 1000ms)scheddetail=1(more detail)
Example:
GODEBUG=schedtrace=1000,scheddetail=1 ./yourappUse this in staging or controlled environments; it can be verbose.
Practical Tips for Scheduler-Friendly Go Code
Keep concurrency bounded
Unbounded concurrency often becomes self-inflicted DDoS. Add backpressure:
- buffered channels
- worker pools
- semaphores
- rate limiting
Prefer blocking to spinning
If waiting for something, block:
- channel receive
sync.Condtime.Timer- context cancellation
Reduce shared memory contention
Design with:
- per-core/per-shard state
- message passing
- batching
Use context for cancellation
When goroutines can outlive requests, cancellation avoids “goroutine leaks,” which affect memory and scheduling overhead.
Be careful with runtime.LockOSThread
This pins a goroutine to an OS thread—useful for:
- thread-affine C libraries
- certain syscalls/GUI contexts
But it reduces scheduler flexibility, and too much pinning can harm throughput.
Don’t over-tune prematurely
The Go scheduler is robust out of the box. Optimize only after you:
- collect traces/profiles
- identify actual bottlenecks (CPU, lock contention, I/O stalls, GC)
FAQ
Is the Golang scheduler preemptive or cooperative?
It’s effectively both. Go historically leaned on cooperative preemption at safe points, but Go 1.14+ added stronger asynchronous preemption to improve fairness and latency.
What does GOMAXPROCS actually control?
It controls the number of Ps—how many goroutines can execute Go code in parallel. You can still have many OS threads (Ms), especially with blocking syscalls or cgo.
Why do I see more OS threads than GOMAXPROCS?
Because threads may be created for:
- blocking syscalls
- cgo calls
- runtime internals (GC, netpoller, sysmon)
GOMAXPROCS limits parallel execution of Go code, not the raw thread count.
When should I use runtime.Gosched()?
Rarely. It yields the processor, letting other goroutines run. It can help in specialized low-level loops, but usually a better design is to block on synchronization primitives or restructure the loop.
Conclusion
The Golang scheduler is the core technology that makes Go’s concurrency practical: it maps massive numbers of goroutines onto a limited set of OS threads using the G-M-P model, per-P run queues, global fairness mechanisms, and work stealing. It integrates tightly with syscalls, the network poller, and garbage collection, and it has evolved significantly—especially around preemption and latency.
If you want to get the best performance from Go:
- bound your concurrency,
- avoid busy-waits,
- reduce lock contention,
- and use tracing/profiling to validate changes.


