Hash tables stand as one of the most fundamental and widely used data structures in all of computer science. At their core, they solve a deceptively simple problem: how do you store and retrieve data by key in constant time? The answer involves a fascinating interplay of mathematical hashing, memory layout design, and collision resolution — a domain where theoretical elegance meets real-world engineering constraints like CPU cache hierarchies, SIMD instruction sets, and denial-of-service attack resilience.
The principle behind a hash table is straightforward. A deterministic hash function transforms a key into an integer, which is then mapped to an index in a fixed-size array. This allows insertions, lookups, and deletions to operate in amortized O(1) time — a performance guarantee that underpins everything from database indexing and compiler symbol tables to in-memory caches and network routing tables. However, this simplicity conceals a critical challenge: collisions. Since the space of possible keys is virtually infinite while the backing array is finite, multiple keys will inevitably map to the same slot. How a hash table handles these collisions defines its character, its performance profile, and its suitability for different workloads.
This research provides a comprehensive deep dive into the internal mechanics of hash tables and the major collision resolution strategies that have evolved over decades of research and engineering. We begin with separate chaining, the classical approach where each bucket holds a linked list of colliding entries — simple to implement but hostile to modern CPU caches. We then move into the family of open addressing techniques, where all entries reside directly within the array. Linear probing offers excellent cache locality but suffers from primary clustering. Quadratic probing mitigates clustering at the cost of requiring careful table sizing. Double hashing eliminates both primary and secondary clustering by using a second hash function to determine probe step sizes.
Beyond these textbook strategies, we explore two more sophisticated modern approaches. Robin Hood hashing introduces a beautifully simple invariant — during insertion, entries with longer probe distances “steal” slots from entries with shorter ones, dramatically equalizing lookup times and enabling early termination during searches. Cuckoo hashing takes a radically different approach, guaranteeing worst-case O(1) lookups by maintaining two hash functions and evicting existing entries to alternate locations on collision, at the cost of more complex insertion logic.
The research goes further by examining how three major programming languages implement hash tables in practice. Python‘s dict uses a compact open-addressing scheme with perturbed probing that preserves insertion order. Go’s map employs a unique hybrid of chaining with 8-entry buckets and top-hash bytes for fast rejection. Rust‘s HashMap, built on Google’s SwissTable design, represents the state of the art — using SIMD instructions to probe 16 slots simultaneously through carefully designed control byte metadata, achieving remarkable performance at load factors as high as 87.5%.
Each strategy is accompanied by complete, working implementations in Python, Go, and Rust, demonstrating not just the algorithms but the practical considerations of memory layout, resizing policies, and deletion mechanics. Through both theoretical analysis and real-world engineering perspective, this research reveals how a data structure born from a simple idea has evolved into one of the most carefully optimized components in modern software systems.
Table of Contents
- Foundational Concepts
- Hash Functions Internals
- Collision Strategy #1 — Separate Chaining
- Collision Strategy #2 — Open Addressing (Linear Probing)
- Collision Strategy #3 — Quadratic Probing
- Collision Strategy #4 — Double Hashing
- Collision Strategy #5 — Robin Hood Hashing
- Collision Strategy #6 — Cuckoo Hashing
- Load Factor, Resizing & Amortized Analysis
- How Real Languages Do It (CPython, Go, Rust)
- Performance Comparison Summary
1. Foundational Concepts
A hash table is a data structure that maps keys → values in amortized O(1) time by using a hash function to compute an index into an array of buckets/slots.
Key ──▶ hash(key) ──▶ index = hash % capacity ──▶ bucket[index]
Core Components
| Component | Description |
|---|---|
| Backing Array | Contiguous memory block of fixed size (capacity) |
| Hash Function | Deterministic function mapping keys to integers |
| Index Mapping | hash(key) % capacity → slot index |
| Collision Strategy | What happens when two keys map to the same slot |
| Load Factor | α = n / capacity (n = number of stored entries) |
| Resize Policy | When and how the table grows/shrinks |
Why Collisions Are Inevitable — The Pigeonhole Principle
If your key space is larger than your table capacity (and it almost always is), multiple keys must map to the same slot. Even with a perfect hash function, by the birthday paradox, collisions appear surprisingly early — with a table of size m, there’s a >50% chance of collision after only ~√m insertions.
2. Hash Functions
Before diving into collision strategies, understanding the hash function is critical.
Properties of a Good Hash Function
- Deterministic: Same key always produces the same hash
- Uniform Distribution: Outputs are spread evenly across the output range
- Avalanche Effect: A small change in input drastically changes output
- Fast to compute: O(1) for fixed-size keys
Common Hash Functions Used in Practice
| Hash Function | Used By | Type |
|---|---|---|
| SipHash 1-3 / 2-4 | Rust HashMap, Python 3.4+ | Keyed (DoS-resistant) |
| AES-based hash | Go runtime | Hardware-accelerated |
| FNV-1a | Common general-purpose | Simple, fast |
| xxHash | Data processing | Very fast, non-crypto |
| MurmurHash3 | Many distributed systems | Fast, good distribution |
| Wyhash | Many modern systems | Extremely fast |
Simple Hash Function Example (FNV-1a style)
Python (FNV-1a inspired hash)
def fnv1a_hash(key: bytes) -> int:
FNV_OFFSET = 2166136261
FNV_PRIME = 16777619
h = FNV_OFFSET
for byte in key:
h ^= byte
h = (h * FNV_PRIME) & 0xFFFFFFFF # keep 32-bit
return h
print(fnv1a_hash(b"hello")) # 1335831723
print(fnv1a_hash(b"hellp")) # completely differentGo (FNV-1a)
package main
import (
"fmt"
"hash/fnv"
)
func fnv1aHash(key string) uint32 {
h := fnv.New32a()
h.Write([]byte(key))
return h.Sum32()
}
func main() {
fmt.Println(fnv1aHash("hello")) // 1335831723
fmt.Println(fnv1aHash("hellp")) // 1553940770 (Completely different)
}
Rust — manual FNV-1a
fn fnv1a_hash(key: &[u8]) -> u32 {
const FNV_OFFSET: u32 = 2166136261;
const FNV_PRIME: u32 = 16777619;
let mut hash = FNV_OFFSET;
for &byte in key {
hash ^= byte as u32;
hash = hash.wrapping_mul(FNV_PRIME);
}
hash
}
fn main() {
println!("{}", fnv1a_hash(b"hello")); // 1335831723
println!("{}", fnv1a_hash(b"hellp")); // 1553940770 (Completely different)
}3. Collision Strategy #1 — Separate Chaining
Concept
Each bucket holds a linked list (or other collection) of all entries that hash to that index. On collision, the new entry is simply appended to the chain.
textIndex 0: ──▶ (k1,v1) ──▶ (k4,v4) ──▶ nil
Index 1: ──▶ nil
Index 2: ──▶ (k2,v2) ──▶ nil
Index 3: ──▶ (k3,v3) ──▶ (k5,v5) ──▶ (k7,v7) ──▶ nil
Index 4: ──▶ nilCharacteristics
| Property | Value |
|---|---|
| Load factor α | Can exceed 1.0 |
| Worst case lookup | O(n) — all keys in one chain |
| Average lookup | O(1 + α) |
| Cache friendliness | Poor — pointer chasing |
| Memory overhead | High — node pointers per entry |
| Deletion | Simple — just unlink |
Python Implementation
class Node:
"""A node in the chain (singly linked list)."""
__slots__ = ('key', 'value', 'next')
def __init__(self, key, value, next_node=None):
self.key = key
self.value = value
self.next = next_node
class ChainingHashTable:
"""Hash table using separate chaining for collision resolution."""
def __init__(self, initial_capacity=8, max_load_factor=0.75):
self._capacity = initial_capacity
self._size = 0
self._max_load_factor = max_load_factor
self._buckets: list[Node | None] = [None] * self._capacity
# --- Core hash & index ---
def _hash(self, key) -> int:
"""Use Python's built-in hash, then map to index."""
return hash(key)
def _index(self, key) -> int:
return self._hash(key) % self._capacity
# --- Load factor ---
@property
def load_factor(self) -> float:
return self._size / self._capacity
# --- INSERT ---
def put(self, key, value):
if self.load_factor >= self._max_load_factor:
self._resize(self._capacity * 2)
idx = self._index(key)
node = self._buckets[idx]
# Walk the chain — update if key exists
while node is not None:
if node.key == key:
node.value = value # update
return
node = node.next
# Prepend new node (O(1))
new_node = Node(key, value, self._buckets[idx])
self._buckets[idx] = new_node
self._size += 1
# --- GET ---
def get(self, key, default=None):
idx = self._index(key)
node = self._buckets[idx]
while node is not None:
if node.key == key:
return node.value
node = node.next
return default
# --- DELETE ---
def delete(self, key) -> bool:
idx = self._index(key)
node = self._buckets[idx]
prev = None
while node is not None:
if node.key == key:
if prev is None:
self._buckets[idx] = node.next
else:
prev.next = node.next
self._size -= 1
return True
prev = node
node = node.next
return False
# --- RESIZE ---
def _resize(self, new_capacity: int):
old_buckets = self._buckets
self._capacity = new_capacity
self._buckets = [None] * new_capacity
self._size = 0
for head in old_buckets:
node = head
while node is not None:
self.put(node.key, node.value)
node = node.next
# --- Utility ---
def __len__(self):
return self._size
def __contains__(self, key):
return self.get(key, _sentinel := object()) is not _sentinel
def __repr__(self):
items = []
for head in self._buckets:
node = head
while node:
items.append(f"{node.key!r}: {node.value!r}")
node = node.next
return "{" + ", ".join(items) + "}"
def debug_structure(self):
"""Visualize the internal bucket structure."""
for i, head in enumerate(self._buckets):
chain = []
node = head
while node:
chain.append(f"({node.key!r},{node.value!r})")
node = node.next
chain_str = " -> ".join(chain) if chain else "empty"
print(f" Bucket[{i}]: {chain_str}")
# --- Demo ---
if __name__ == "__main__":
ht = ChainingHashTable(initial_capacity=4)
for word in ["apple", "banana", "cherry", "date", "elderberry", "fig"]:
ht.put(word, len(word))
print(f"Size: {len(ht)}, Load Factor: {ht.load_factor:.2f}")
ht.debug_structure()
print(f"\nget('cherry') = {ht.get('cherry')}")
ht.delete("banana")
print(f"After deleting 'banana': 'banana' in ht = {'banana' in ht}")Go Implementation
package main
import "fmt"
// ---------- Separate Chaining Hash Table ----------
type entry struct {
key string
value interface{}
next *entry
}
type ChainingHashTable struct {
buckets []*entry
capacity int
size int
maxLoadFactor float64
}
func NewChainingHashTable(capacity int) *ChainingHashTable {
return &ChainingHashTable{
buckets: make([]*entry, capacity),
capacity: capacity,
maxLoadFactor: 0.75,
}
}
// Simple FNV-1a hash
func (ht *ChainingHashTable) hash(key string) int {
var h uint32 = 2166136261
for i := 0; i < len(key); i++ {
h ^= uint32(key[i])
h *= 16777619
}
return int(h)
}
func (ht *ChainingHashTable) index(key string) int {
return ht.hash(key) % ht.capacity
}
func (ht *ChainingHashTable) loadFactor() float64 {
return float64(ht.size) / float64(ht.capacity)
}
// Put inserts or updates a key-value pair
func (ht *ChainingHashTable) Put(key string, value interface{}) {
if ht.loadFactor() >= ht.maxLoadFactor {
ht.resize(ht.capacity * 2)
}
idx := ht.index(key)
node := ht.buckets[idx]
for node != nil {
if node.key == key {
node.value = value // update
return
}
node = node.next
}
// Prepend
newEntry := &entry{key: key, value: value, next: ht.buckets[idx]}
ht.buckets[idx] = newEntry
ht.size++
}
// Get retrieves a value by key
func (ht *ChainingHashTable) Get(key string) (interface{}, bool) {
idx := ht.index(key)
node := ht.buckets[idx]
for node != nil {
if node.key == key {
return node.value, true
}
node = node.next
}
return nil, false
}
// Delete removes a key
func (ht *ChainingHashTable) Delete(key string) bool {
idx := ht.index(key)
node := ht.buckets[idx]
var prev *entry
for node != nil {
if node.key == key {
if prev == nil {
ht.buckets[idx] = node.next
} else {
prev.next = node.next
}
ht.size--
return true
}
prev = node
node = node.next
}
return false
}
func (ht *ChainingHashTable) resize(newCapacity int) {
oldBuckets := ht.buckets
ht.buckets = make([]*entry, newCapacity)
ht.capacity = newCapacity
ht.size = 0
for _, head := range oldBuckets {
node := head
for node != nil {
ht.Put(node.key, node.value)
node = node.next
}
}
}
func (ht *ChainingHashTable) DebugPrint() {
for i, head := range ht.buckets {
chain := ""
node := head
for node != nil {
if chain != "" {
chain += " -> "
}
chain += fmt.Sprintf("(%s,%v)", node.key, node.value)
node = node.next
}
if chain == "" {
chain = "empty"
}
fmt.Printf(" Bucket[%d]: %s\n", i, chain)
}
}
func main() {
ht := NewChainingHashTable(4)
words := []string{"apple", "banana", "cherry", "date", "elderberry"}
for _, w := range words {
ht.Put(w, len(w))
}
fmt.Printf("Size: %d, Load Factor: %.2f\n", ht.size, ht.loadFactor())
ht.DebugPrint()
if val, ok := ht.Get("cherry"); ok {
fmt.Printf("\nGet('cherry') = %v\n", val)
}
}Rust Implementation
use std::collections::hash_map::DefaultHasher;
use std::hash::{Hash, Hasher};
// ---------- Separate Chaining Hash Table ----------
struct Entry<K, V> {
key: K,
value: V,
}
pub struct ChainingHashTable<K, V> {
buckets: Vec<Vec<Entry<K, V>>>, // Vec of Vecs instead of linked lists
capacity: usize,
size: usize,
max_load_factor: f64,
}
impl<K: Hash + Eq + Clone + std::fmt::Debug, V: Clone + std::fmt::Debug>
ChainingHashTable<K, V>
{
pub fn new(capacity: usize) -> Self {
let mut buckets = Vec::with_capacity(capacity);
for _ in 0..capacity {
buckets.push(Vec::new());
}
Self {
buckets,
capacity,
size: 0,
max_load_factor: 0.75,
}
}
fn hash_index(&self, key: &K) -> usize {
let mut hasher = DefaultHasher::new();
key.hash(&mut hasher);
(hasher.finish() as usize) % self.capacity
}
pub fn load_factor(&self) -> f64 {
self.size as f64 / self.capacity as f64
}
pub fn put(&mut self, key: K, value: V) {
if self.load_factor() >= self.max_load_factor {
self.resize(self.capacity * 2);
}
let idx = self.hash_index(&key);
// Update if exists
for entry in &mut self.buckets[idx] {
if entry.key == key {
entry.value = value;
return;
}
}
// Push new entry
self.buckets[idx].push(Entry { key, value });
self.size += 1;
}
pub fn get(&self, key: &K) -> Option<&V> {
let idx = self.hash_index(key);
for entry in &self.buckets[idx] {
if entry.key == *key {
return Some(&entry.value);
}
}
None
}
pub fn delete(&mut self, key: &K) -> bool {
let idx = self.hash_index(key);
if let Some(pos) = self.buckets[idx].iter().position(|e| e.key == *key) {
self.buckets[idx].swap_remove(pos);
self.size -= 1;
return true;
}
false
}
fn resize(&mut self, new_capacity: usize) {
let old_buckets = std::mem::replace(
&mut self.buckets,
(0..new_capacity).map(|_| Vec::new()).collect(),
);
self.capacity = new_capacity;
self.size = 0;
for bucket in old_buckets {
for entry in bucket {
self.put(entry.key, entry.value);
}
}
}
pub fn debug_print(&self) {
for (i, bucket) in self.buckets.iter().enumerate() {
if bucket.is_empty() {
println!(" Bucket[{}]: empty", i);
} else {
let entries: Vec<String> = bucket
.iter()
.map(|e| format!("({:?},{:?})", e.key, e.value))
.collect();
println!(" Bucket[{}]: {}", i, entries.join(" -> "));
}
}
}
}
fn main() {
let mut ht = ChainingHashTable::new(4);
for word in &["apple", "banana", "cherry", "date", "elderberry"] {
ht.put(word.to_string(), word.len());
}
println!("Size: {}, Load Factor: {:.2}", ht.size, ht.load_factor());
ht.debug_print();
if let Some(val) = ht.get(&"cherry".to_string()) {
println!("\nget(\"cherry\") = {}", val);
}
}4. Collision Strategy #2 — Open Addressing: Linear Probing
Concept
All entries live directly inside the array. On collision, we probe the next slot sequentially:
textprobe(key, i) = (hash(key) + i) % capacity for i = 0, 1, 2, 3, ...textInsert "cat" → hash = 3
Insert "dog" → hash = 3 (collision!)
→ try slot 4... empty! Place here.
Insert "rat" → hash = 3 (collision!)
→ try slot 4... occupied! try slot 5... empty! Place here.
Index: 0 1 2 [3] [4] [5] 6 7
nil nil nil cat dog rat nil nilThe Clustering Problem
Linear probing suffers from primary clustering: consecutive occupied slots form long runs, and the probability of a slot extending a cluster is proportional to the cluster’s length. This creates a feedback loop.
textPerformance degrades as clusters grow:
α = 0.5 → avg probes ≈ 1.5
α = 0.7 → avg probes ≈ 2.17
α = 0.9 → avg probes ≈ 5.5
α = 0.99 → avg probes ≈ 50.5Deletion: Tombstones vs. Backward Shift
Two approaches:
- Tombstones (DELETED markers): Mark slot as deleted, don’t break probe chains. Simple but pollutes the table.
- Backward-shift deletion: Shift subsequent entries backward to fill the gap. More complex but keeps the table clean.
Python Implementation (with Backward-Shift Delete)
from enum import Enum
from typing import Any
class SlotState(Enum):
EMPTY = 0
OCCUPIED = 1
class LinearProbingHashTable:
"""Hash table with linear probing and backward-shift deletion."""
def __init__(self, initial_capacity=8, max_load_factor=0.6):
self._capacity = initial_capacity
self._size = 0
self._max_load = max_load_factor
# Parallel arrays for cache-friendliness
self._keys = [None] * self._capacity
self._values = [None] * self._capacity
self._states = [SlotState.EMPTY] * self._capacity
def _hash(self, key) -> int:
return hash(key)
def _index(self, key) -> int:
return self._hash(key) % self._capacity
@property
def load_factor(self) -> float:
return self._size / self._capacity
# --- INSERT ---
def put(self, key, value):
if self.load_factor >= self._max_load:
self._resize(self._capacity * 2)
idx = self._index(key)
while True:
state = self._states[idx]
if state == SlotState.EMPTY:
# Place here
self._keys[idx] = key
self._values[idx] = value
self._states[idx] = SlotState.OCCUPIED
self._size += 1
return
elif self._keys[idx] == key:
# Update existing
self._values[idx] = value
return
# Linear probe: next slot
idx = (idx + 1) % self._capacity
# --- GET ---
def get(self, key, default=None):
idx = self._index(key)
while True:
state = self._states[idx]
if state == SlotState.EMPTY:
return default
if self._keys[idx] == key:
return self._values[idx]
idx = (idx + 1) % self._capacity
# --- DELETE (backward-shift) ---
def delete(self, key) -> bool:
idx = self._index(key)
# Find the key
while True:
if self._states[idx] == SlotState.EMPTY:
return False # not found
if self._keys[idx] == key:
break
idx = (idx + 1) % self._capacity
# Found at idx — now backward-shift
while True:
next_idx = (idx + 1) % self._capacity
# If next slot is empty or the key at next_idx is at its natural
# position (i.e., it wasn't displaced), we can stop
if (self._states[next_idx] == SlotState.EMPTY or
self._index(self._keys[next_idx]) == next_idx):
# Clear current slot
self._keys[idx] = None
self._values[idx] = None
self._states[idx] = SlotState.EMPTY
self._size -= 1
return True
# Check if the entry at next_idx was displaced past idx
# i.e., its natural position is at or before idx in the probe chain
natural = self._index(self._keys[next_idx])
# Determine if natural position is "before or at" idx
# considering wrapping
if self._is_between(natural, idx, next_idx):
# This entry belongs in a position ≤ idx, so shift it back
self._keys[idx] = self._keys[next_idx]
self._values[idx] = self._values[next_idx]
idx = next_idx
else:
# Clear current and stop
self._keys[idx] = None
self._values[idx] = None
self._states[idx] = SlotState.EMPTY
self._size -= 1
return True
def _is_between(self, natural, gap, current):
"""Check if natural position is in the range (gap, current] circularly,
meaning the entry at current was displaced past gap."""
if gap < current:
return not (gap < natural <= current)
else: # wraps around
return natural <= gap and natural > current
# --- RESIZE ---
def _resize(self, new_capacity):
old_keys = self._keys
old_values = self._values
old_states = self._states
self._capacity = new_capacity
self._keys = [None] * new_capacity
self._values = [None] * new_capacity
self._states = [SlotState.EMPTY] * new_capacity
self._size = 0
for i in range(len(old_keys)):
if old_states[i] == SlotState.OCCUPIED:
self.put(old_keys[i], old_values[i])
# --- Utility ---
def __len__(self):
return self._size
def __contains__(self, key):
sentinel = object()
return self.get(key, sentinel) is not sentinel
def debug_print(self):
for i in range(self._capacity):
state = self._states[i]
if state == SlotState.OCCUPIED:
natural = self._index(self._keys[i])
displacement = (i - natural) % self._capacity
print(f" [{i}] {self._keys[i]!r} => {self._values[i]!r} "
f"(natural={natural}, displaced={displacement})")
else:
print(f" [{i}] ---")
# --- Demo ---
if __name__ == "__main__":
ht = LinearProbingHashTable(initial_capacity=16)
words = ["apple", "banana", "cherry", "date", "elderberry",
"fig", "grape", "honeydew"]
for w in words:
ht.put(w, len(w))
print(f"Size: {len(ht)}, Load: {ht.load_factor:.2f}")
ht.debug_print()
print(f"\nget('fig') = {ht.get('fig')}")
ht.delete("cherry")
print("\nAfter deleting 'cherry':")
ht.debug_print()Golang Implementation (with Backward-Shift Delete)
package main
import "fmt"
const (
stateEmpty = 0
stateOccupied = 1
)
type LinearProbingHT struct {
keys []string
values []int
states []int
capacity int
size int
maxLoad float64
}
func NewLinearProbingHT(capacity int) *LinearProbingHT {
return &LinearProbingHT{
keys: make([]string, capacity),
values: make([]int, capacity),
states: make([]int, capacity),
capacity: capacity,
maxLoad: 0.6,
}
}
func (ht *LinearProbingHT) hash(key string) int {
var h uint32 = 2166136261
for i := 0; i < len(key); i++ {
h ^= uint32(key[i])
h *= 16777619
}
return int(h)
}
func (ht *LinearProbingHT) index(key string) int {
h := ht.hash(key)
idx := h % ht.capacity
if idx < 0 {
idx += ht.capacity
}
return idx
}
func (ht *LinearProbingHT) loadFactor() float64 {
return float64(ht.size) / float64(ht.capacity)
}
func (ht *LinearProbingHT) Put(key string, value int) {
if ht.loadFactor() >= ht.maxLoad {
ht.resize(ht.capacity * 2)
}
idx := ht.index(key)
for {
if ht.states[idx] == stateEmpty {
ht.keys[idx] = key
ht.values[idx] = value
ht.states[idx] = stateOccupied
ht.size++
return
}
if ht.keys[idx] == key {
ht.values[idx] = value
return
}
idx = (idx + 1) % ht.capacity
}
}
func (ht *LinearProbingHT) Get(key string) (int, bool) {
idx := ht.index(key)
for {
if ht.states[idx] == stateEmpty {
return 0, false
}
if ht.keys[idx] == key {
return ht.values[idx], true
}
idx = (idx + 1) % ht.capacity
}
}
// Delete with backward shift
func (ht *LinearProbingHT) Delete(key string) bool {
idx := ht.index(key)
// Find key
for {
if ht.states[idx] == stateEmpty {
return false
}
if ht.keys[idx] == key {
break
}
idx = (idx + 1) % ht.capacity
}
// Backward-shift loop
for {
next := (idx + 1) % ht.capacity
if ht.states[next] == stateEmpty {
break
}
natural := ht.index(ht.keys[next])
// Check if next entry was displaced past idx
if ht.shouldShift(natural, idx, next) {
ht.keys[idx] = ht.keys[next]
ht.values[idx] = ht.values[next]
idx = next
} else {
break
}
}
ht.keys[idx] = ""
ht.values[idx] = 0
ht.states[idx] = stateEmpty
ht.size--
return true
}
func (ht *LinearProbingHT) shouldShift(natural, gap, current int) bool {
if gap < current {
return natural <= gap || natural > current
}
return natural <= gap && natural > current
}
func (ht *LinearProbingHT) resize(newCap int) {
oldKeys := ht.keys
oldValues := ht.values
oldStates := ht.states
ht.keys = make([]string, newCap)
ht.values = make([]int, newCap)
ht.states = make([]int, newCap)
ht.capacity = newCap
ht.size = 0
for i, state := range oldStates {
if state == stateOccupied {
ht.Put(oldKeys[i], oldValues[i])
}
}
}
func (ht *LinearProbingHT) DebugPrint() {
for i := 0; i < ht.capacity; i++ {
if ht.states[i] == stateOccupied {
natural := ht.index(ht.keys[i])
disp := (i - natural + ht.capacity) % ht.capacity
fmt.Printf(" [%d] %s => %d (natural=%d, disp=%d)\n",
i, ht.keys[i], ht.values[i], natural, disp)
} else {
fmt.Printf(" [%d] ---\n", i)
}
}
}
func main() {
ht := NewLinearProbingHT(16)
words := []string{"apple", "banana", "cherry", "date", "elderberry", "fig"}
for _, w := range words {
ht.Put(w, len(w))
}
fmt.Printf("Size: %d, Load: %.2f\n", ht.size, ht.loadFactor())
ht.DebugPrint()
if val, ok := ht.Get("fig"); ok {
fmt.Printf("\nGet(\"fig\") = %d\n", val)
}
}Rust Implementation (with Backward-Shift Delete)
use std::collections::hash_map::DefaultHasher;
use std::hash::{Hash, Hasher};
#[derive(Clone, Copy, PartialEq)]
enum SlotState {
Empty,
Occupied,
}
pub struct LinearProbingHashTable<K, V> {
keys: Vec<Option<K>>,
values: Vec<Option<V>>,
states: Vec<SlotState>,
capacity: usize,
size: usize,
max_load: f64,
}
impl<K: Hash + Eq + Clone + std::fmt::Debug, V: Clone + std::fmt::Debug>
LinearProbingHashTable<K, V>
{
pub fn new(capacity: usize) -> Self {
Self {
keys: vec![None; capacity],
values: vec![None; capacity],
states: vec![SlotState::Empty; capacity],
capacity,
size: 0,
max_load: 0.6,
}
}
fn hash_index(&self, key: &K) -> usize {
let mut hasher = DefaultHasher::new();
key.hash(&mut hasher);
(hasher.finish() as usize) % self.capacity
}
pub fn load_factor(&self) -> f64 {
self.size as f64 / self.capacity as f64
}
pub fn put(&mut self, key: K, value: V) {
if self.load_factor() >= self.max_load {
self.resize(self.capacity * 2);
}
let mut idx = self.hash_index(&key);
loop {
match self.states[idx] {
SlotState::Empty => {
self.keys[idx] = Some(key);
self.values[idx] = Some(value);
self.states[idx] = SlotState::Occupied;
self.size += 1;
return;
}
SlotState::Occupied => {
if self.keys[idx].as_ref() == Some(&key) {
self.values[idx] = Some(value);
return;
}
}
}
idx = (idx + 1) % self.capacity;
}
}
pub fn get(&self, key: &K) -> Option<&V> {
let mut idx = self.hash_index(key);
loop {
match self.states[idx] {
SlotState::Empty => return None,
SlotState::Occupied => {
if self.keys[idx].as_ref() == Some(key) {
return self.values[idx].as_ref();
}
}
}
idx = (idx + 1) % self.capacity;
}
}
pub fn delete(&mut self, key: &K) -> bool {
let mut idx = self.hash_index(key);
// Find the key
loop {
if self.states[idx] == SlotState::Empty {
return false;
}
if self.keys[idx].as_ref() == Some(key) {
break;
}
idx = (idx + 1) % self.capacity;
}
// Backward-shift
loop {
let next = (idx + 1) % self.capacity;
if self.states[next] == SlotState::Empty {
break;
}
let natural = self.hash_index(self.keys[next].as_ref().unwrap());
if self.should_shift(natural, idx, next) {
self.keys[idx] = self.keys[next].clone();
self.values[idx] = self.values[next].clone();
idx = next;
} else {
break;
}
}
self.keys[idx] = None;
self.values[idx] = None;
self.states[idx] = SlotState::Empty;
self.size -= 1;
true
}
fn should_shift(&self, natural: usize, gap: usize, current: usize) -> bool {
if gap < current {
natural <= gap || natural > current
} else {
natural <= gap && natural > current
}
}
fn resize(&mut self, new_capacity: usize) {
let old_keys = std::mem::replace(&mut self.keys, vec![None; new_capacity]);
let old_values = std::mem::replace(&mut self.values, vec![None; new_capacity]);
let old_states =
std::mem::replace(&mut self.states, vec![SlotState::Empty; new_capacity]);
self.capacity = new_capacity;
self.size = 0;
for i in 0..old_keys.len() {
if old_states[i] == SlotState::Occupied {
if let (Some(k), Some(v)) = (old_keys[i].clone(), old_values[i].clone()) {
self.put(k, v);
}
}
}
}
pub fn debug_print(&self) {
for i in 0..self.capacity {
match self.states[i] {
SlotState::Occupied => {
let k = self.keys[i].as_ref().unwrap();
let v = self.values[i].as_ref().unwrap();
let natural = self.hash_index(k);
let disp = (i + self.capacity - natural) % self.capacity;
println!(" [{}] {:?} => {:?} (natural={}, disp={})",
i, k, v, natural, disp);
}
SlotState::Empty => {
println!(" [{}] ---", i);
}
}
}
}
}
fn main() {
let mut ht = LinearProbingHashTable::new(16);
for word in &["apple", "banana", "cherry", "date", "elderberry", "fig"] {
ht.put(word.to_string(), word.len());
}
println!("Size: {}, Load: {:.2}", ht.size, ht.load_factor());
ht.debug_print();
if let Some(val) = ht.get(&"fig".to_string()) {
println!("\nget(\"fig\") = {}", val);
}
}5. Collision Strategy #3 — Quadratic Probing
Concept
Instead of probing linearly (+1, +2, +3, ...), quadratic probing uses a quadratic function:
textprobe(key, i) = (hash(key) + c1*i + c2*i²) % capacityCommon choices: c1 = 0, c2 = 1 → probing sequence: +0, +1, +4, +9, +16, ...
Or: c1 = 1/2, c2 = 1/2 → +0, +1, +3, +6, +10, ... (triangular numbers)
Key Insight: Table Size Matters
Theorem: If the table size is prime and the load factor ≤ 0.5, quadratic probing with h(k) + i² is guaranteed to find an empty slot and visits distinct slots for i = 0, 1, ..., (m-1)/2.
With power-of-two sizes, use triangular numbers: h(k) + i*(i+1)/2 — guaranteed to probe all slots.
Eliminates Primary Clustering, But…
Quadratic probing eliminates primary clustering but still suffers from secondary clustering: keys that hash to the same initial index follow the same probe sequence.
Python Implementation
class QuadraticProbingHashTable:
"""
Quadratic probing with triangular numbers: probe(i) = i*(i+1)//2
Works with power-of-two table sizes.
"""
EMPTY = object()
DELETED = object() # tombstone approach for simplicity
def __init__(self, initial_capacity=8, max_load=0.5):
# Ensure power of two
self._capacity = initial_capacity
self._max_load = max_load
self._size = 0
self._keys = [self.EMPTY] * self._capacity
self._values = [None] * self._capacity
def _index(self, key) -> int:
return hash(key) % self._capacity
@property
def load_factor(self):
return self._size / self._capacity
def put(self, key, value):
if self.load_factor >= self._max_load:
self._resize(self._capacity * 2)
idx = self._index(key)
first_deleted = -1
i = 0
while True:
probe_idx = (idx + i * (i + 1) // 2) % self._capacity
if self._keys[probe_idx] is self.EMPTY:
target = first_deleted if first_deleted != -1 else probe_idx
self._keys[target] = key
self._values[target] = value
self._size += 1
return
elif self._keys[probe_idx] is self.DELETED:
if first_deleted == -1:
first_deleted = probe_idx
elif self._keys[probe_idx] == key:
self._values[probe_idx] = value
return
i += 1
def get(self, key, default=None):
idx = self._index(key)
i = 0
while True:
probe_idx = (idx + i * (i + 1) // 2) % self._capacity
if self._keys[probe_idx] is self.EMPTY:
return default
if self._keys[probe_idx] == key:
return self._values[probe_idx]
i += 1
def delete(self, key) -> bool:
idx = self._index(key)
i = 0
while True:
probe_idx = (idx + i * (i + 1) // 2) % self._capacity
if self._keys[probe_idx] is self.EMPTY:
return False
if self._keys[probe_idx] == key:
self._keys[probe_idx] = self.DELETED
self._values[probe_idx] = None
self._size -= 1
return True
i += 1
def _resize(self, new_cap):
old_keys = self._keys
old_vals = self._values
self._capacity = new_cap
self._keys = [self.EMPTY] * new_cap
self._values = [None] * new_cap
self._size = 0
for i, k in enumerate(old_keys):
if k is not self.EMPTY and k is not self.DELETED:
self.put(k, old_vals[i])
def debug_print(self):
for i in range(self._capacity):
k = self._keys[i]
if k is self.EMPTY:
print(f" [{i}] ---")
elif k is self.DELETED:
print(f" [{i}] TOMBSTONE")
else:
print(f" [{i}] {k!r} => {self._values[i]!r}")
if __name__ == "__main__":
ht = QuadraticProbingHashTable(initial_capacity=16)
for w in ["alpha", "bravo", "charlie", "delta", "echo", "foxtrot"]:
ht.put(w, w.upper())
print(f"Size: {ht._size}, Load: {ht.load_factor:.2f}")
ht.debug_print()
print(f"\nget('echo') = {ht.get('echo')}")6. Collision Strategy #4 — Double Hashing
Concept
Uses a second hash function to determine the probe step size, eliminating both primary and secondary clustering:
textprobe(key, i) = (h1(key) + i * h2(key)) % capacityConstraint: h2(key) must never return 0 (otherwise we’d loop in place) and should be coprime with the table capacity. Common approach: make capacity prime, and use h2(key) = PRIME - (hash(key) % PRIME) where PRIME < capacity.
Python Implementation
class DoubleHashingTable:
"""Hash table with double hashing for collision resolution."""
EMPTY = object()
DELETED = object()
def __init__(self, capacity=13, max_load=0.6):
# Capacity should be prime for best results
self._capacity = capacity
self._max_load = max_load
self._size = 0
self._keys = [self.EMPTY] * capacity
self._values = [None] * capacity
# Second prime, smaller than capacity
self._prime2 = self._smaller_prime(capacity)
@staticmethod
def _smaller_prime(n):
"""Find largest prime smaller than n."""
for candidate in range(n - 1, 1, -1):
if all(candidate % i != 0 for i in range(2, int(candidate**0.5) + 1)):
return candidate
return 1
def _h1(self, key) -> int:
return hash(key) % self._capacity
def _h2(self, key) -> int:
"""Second hash — guaranteed non-zero and coprime with capacity."""
return self._prime2 - (hash(key) % self._prime2)
def _probe(self, key, i) -> int:
return (self._h1(key) + i * self._h2(key)) % self._capacity
@property
def load_factor(self):
return self._size / self._capacity
def put(self, key, value):
if self.load_factor >= self._max_load:
self._resize()
first_deleted = -1
for i in range(self._capacity):
idx = self._probe(key, i)
if self._keys[idx] is self.EMPTY:
target = first_deleted if first_deleted != -1 else idx
self._keys[target] = key
self._values[target] = value
self._size += 1
return
elif self._keys[idx] is self.DELETED:
if first_deleted == -1:
first_deleted = idx
elif self._keys[idx] == key:
self._values[idx] = value
return
# Table is full (shouldn't happen with proper load management)
raise RuntimeError("Hash table is full")
def get(self, key, default=None):
for i in range(self._capacity):
idx = self._probe(key, i)
if self._keys[idx] is self.EMPTY:
return default
if self._keys[idx] == key:
return self._values[idx]
return default
def delete(self, key) -> bool:
for i in range(self._capacity):
idx = self._probe(key, i)
if self._keys[idx] is self.EMPTY:
return False
if self._keys[idx] == key:
self._keys[idx] = self.DELETED
self._values[idx] = None
self._size -= 1
return True
return False
@staticmethod
def _next_prime(n):
"""Find next prime >= n."""
candidate = n
while True:
if candidate < 2:
candidate = 2
if all(candidate % i != 0 for i in range(2, int(candidate**0.5) + 1)):
return candidate
candidate += 1
def _resize(self):
new_cap = self._next_prime(self._capacity * 2)
old_keys, old_vals = self._keys, self._values
self._capacity = new_cap
self._prime2 = self._smaller_prime(new_cap)
self._keys = [self.EMPTY] * new_cap
self._values = [None] * new_cap
self._size = 0
for i, k in enumerate(old_keys):
if k is not self.EMPTY and k is not self.DELETED:
self.put(k, old_vals[i])
def debug_print(self):
for i in range(self._capacity):
k = self._keys[i]
if k is self.EMPTY:
print(f" [{i:2d}] ---")
elif k is self.DELETED:
print(f" [{i:2d}] TOMBSTONE")
else:
print(f" [{i:2d}] {k!r} => {self._values[i]!r} "
f"(h1={self._h1(k)}, h2={self._h2(k)})")
if __name__ == "__main__":
ht = DoubleHashingTable(capacity=13)
for w in ["sun", "moon", "star", "planet", "comet", "nebula", "galaxy"]:
ht.put(w, w.upper())
print(f"Size: {ht._size}, Cap: {ht._capacity}, Load: {ht.load_factor:.2f}")
print(f"Prime2: {ht._prime2}")
ht.debug_print()
print(f"\nget('comet') = {ht.get('comet')}")7. Collision Strategy #5 — Robin Hood Hashing
Concept
A variant of linear probing that equalizes probe distances. The key insight: during insertion, if the entry being inserted has traveled further from its home than the entry currently occupying a slot, they swap — the “rich” (short displacement) entry gives up its slot to the “poor” (long displacement) entry.
textRobin Hood Rule:
If displacement(new_entry) > displacement(existing_entry):
swap them, continue inserting the displaced entryWhy It’s Brilliant
- Dramatically reduces variance in probe lengths
- Expected maximum probe length: O(log n) instead of O(n)
- Lookups can terminate early: if you’ve probed further than the displacement of the current slot, the key doesn’t exist
- Great cache behavior (like all linear probing variants)
Visual Example
textInserting entries with their "displacement" (distance from home):
Before Robin Hood:
[0] A (disp=0) [1] B (disp=0) [2] C (disp=2) [3] D (disp=3)
Some entries are displaced a lot, others not at all.
After Robin Hood rebalancing:
[0] A (disp=0) [1] X (disp=1) [2] B (disp=1) [3] C (disp=1)
DisplaIcements are much more uniform!Python Implementation
class RobinHoodHashTable:
"""Robin Hood hashing: steal from the rich, give to the poor."""
def __init__(self, initial_capacity=8, max_load=0.7):
self._capacity = initial_capacity
self._max_load = max_load
self._size = 0
self._keys = [None] * self._capacity
self._values = [None] * self._capacity
self._occupied = [False] * self._capacity
def _hash(self, key) -> int:
return hash(key) % self._capacity
def _displacement(self, key, current_idx) -> int:
"""How far this key is from its home slot."""
home = self._hash(key)
return (current_idx - home + self._capacity) % self._capacity
@property
def load_factor(self):
return self._size / self._capacity
def put(self, key, value):
if self.load_factor >= self._max_load:
self._resize(self._capacity * 2)
idx = self._hash(key)
incoming_key = key
incoming_value = value
incoming_disp = 0
while True:
if not self._occupied[idx]:
# Empty slot — place here
self._keys[idx] = incoming_key
self._values[idx] = incoming_value
self._occupied[idx] = True
self._size += 1
return
if self._keys[idx] == incoming_key:
# Update existing
self._values[idx] = incoming_value
return
# Compare displacements
existing_disp = self._displacement(self._keys[idx], idx)
if incoming_disp > existing_disp:
# ROBIN HOOD: steal from the rich!
# Swap incoming with existing
self._keys[idx], incoming_key = incoming_key, self._keys[idx]
self._values[idx], incoming_value = incoming_value, self._values[idx]
incoming_disp = existing_disp
# Continue probing
idx = (idx + 1) % self._capacity
incoming_disp += 1
def get(self, key, default=None):
idx = self._hash(key)
disp = 0
while True:
if not self._occupied[idx]:
return default
if self._keys[idx] == key:
return self._values[idx]
# EARLY TERMINATION: if our probe distance exceeds
# the displacement of the entry at this slot,
# then our key cannot exist further along
existing_disp = self._displacement(self._keys[idx], idx)
if disp > existing_disp:
return default # key definitely not in table
idx = (idx + 1) % self._capacity
disp += 1
def delete(self, key) -> bool:
idx = self._hash(key)
disp = 0
# Find the key
while True:
if not self._occupied[idx]:
return False
if self._keys[idx] == key:
break
existing_disp = self._displacement(self._keys[idx], idx)
if disp > existing_disp:
return False
idx = (idx + 1) % self._capacity
disp += 1
# Backward-shift deletion
while True:
next_idx = (idx + 1) % self._capacity
if not self._occupied[next_idx]:
break
next_disp = self._displacement(self._keys[next_idx], next_idx)
if next_disp == 0:
break # next entry is at its home; can't shift
# Shift backward
self._keys[idx] = self._keys[next_idx]
self._values[idx] = self._values[next_idx]
idx = next_idx
# Clear the final slot
self._keys[idx] = None
self._values[idx] = None
self._occupied[idx] = False
self._size -= 1
return True
def _resize(self, new_cap):
old_keys = self._keys
old_values = self._values
old_occupied = self._occupied
self._capacity = new_cap
self._keys = [None] * new_cap
self._values = [None] * new_cap
self._occupied = [False] * new_cap
self._size = 0
for i in range(len(old_keys)):
if old_occupied[i]:
self.put(old_keys[i], old_values[i])
def __len__(self):
return self._size
def stats(self):
"""Show displacement statistics — the hallmark of Robin Hood."""
displacements = []
for i in range(self._capacity):
if self._occupied[i]:
d = self._displacement(self._keys[i], i)
displacements.append(d)
if not displacements:
print(" Table is empty")
return
print(f" Entries: {len(displacements)}")
print(f" Max displacement: {max(displacements)}")
print(f" Avg displacement: {sum(displacements)/len(displacements):.2f}")
print(f" Displacement distribution: ", end="")
from collections import Counter
dist = Counter(displacements)
for d in sorted(dist.keys()):
print(f"d={d}:{dist[d]} ", end="")
print()
def debug_print(self):
for i in range(self._capacity):
if self._occupied[i]:
d = self._displacement(self._keys[i], i)
home = self._hash(self._keys[i])
print(f" [{i:2d}] {self._keys[i]!r:>15} => {self._values[i]!r:<10} "
f"home={home:2d} disp={d}")
else:
print(f" [{i:2d}] ---")
if __name__ == "__main__":
ht = RobinHoodHashTable(initial_capacity=16, max_load=0.7)
words = ["alpha", "bravo", "charlie", "delta", "echo",
"foxtrot", "golf", "hotel", "india", "juliet"]
for w in words:
ht.put(w, len(w))
print(f"Size: {len(ht)}, Load: {ht.load_factor:.2f}\n")
ht.debug_print()
print("\nDisplacement statistics:")
ht.stats()
print(f"\nget('hotel') = {ht.get('hotel')}")Golang Implementation:
package main
import "fmt"
type RobinHoodHT struct {
keys []string
values []int
occupied []bool
capacity int
size int
maxLoad float64
}
func NewRobinHoodHT(capacity int) *RobinHoodHT {
return &RobinHoodHT{
keys: make([]string, capacity),
values: make([]int, capacity),
occupied: make([]bool, capacity),
capacity: capacity,
maxLoad: 0.7,
}
}
func (ht *RobinHoodHT) hash(key string) int {
var h uint32 = 2166136261
for i := 0; i < len(key); i++ {
h ^= uint32(key[i])
h *= 16777619
}
return int(h % uint32(ht.capacity))
}
func (ht *RobinHoodHT) displacement(key string, idx int) int {
home := ht.hash(key)
return (idx - home + ht.capacity) % ht.capacity
}
func (ht *RobinHoodHT) loadFactor() float64 {
return float64(ht.size) / float64(ht.capacity)
}
func (ht *RobinHoodHT) Put(key string, value int) {
if ht.loadFactor() >= ht.maxLoad {
ht.resize(ht.capacity * 2)
}
idx := ht.hash(key)
inKey, inVal := key, value
inDisp := 0
for {
if !ht.occupied[idx] {
ht.keys[idx] = inKey
ht.values[idx] = inVal
ht.occupied[idx] = true
ht.size++
return
}
if ht.keys[idx] == inKey {
ht.values[idx] = inVal
return
}
existDisp := ht.displacement(ht.keys[idx], idx)
if inDisp > existDisp {
// Robin Hood swap!
ht.keys[idx], inKey = inKey, ht.keys[idx]
ht.values[idx], inVal = inVal, ht.values[idx]
inDisp = existDisp
}
idx = (idx + 1) % ht.capacity
inDisp++
}
}
func (ht *RobinHoodHT) Get(key string) (int, bool) {
idx := ht.hash(key)
disp := 0
for {
if !ht.occupied[idx] {
return 0, false
}
if ht.keys[idx] == key {
return ht.values[idx], true
}
existDisp := ht.displacement(ht.keys[idx], idx)
if disp > existDisp {
return 0, false // early termination
}
idx = (idx + 1) % ht.capacity
disp++
}
}
func (ht *RobinHoodHT) resize(newCap int) {
oldKeys := ht.keys
oldVals := ht.values
oldOcc := ht.occupied
ht.keys = make([]string, newCap)
ht.values = make([]int, newCap)
ht.occupied = make([]bool, newCap)
ht.capacity = newCap
ht.size = 0
for i, occ := range oldOcc {
if occ {
ht.Put(oldKeys[i], oldVals[i])
}
}
}
func (ht *RobinHoodHT) Stats() {
maxDisp := 0
totalDisp := 0
for i := 0; i < ht.capacity; i++ {
if ht.occupied[i] {
d := ht.displacement(ht.keys[i], i)
totalDisp += d
if d > maxDisp {
maxDisp = d
}
}
}
if ht.size > 0 {
fmt.Printf(" Max displacement: %d, Avg: %.2f\n",
maxDisp, float64(totalDisp)/float64(ht.size))
}
}
func main() {
ht := NewRobinHoodHT(16)
words := []string{"alpha", "bravo", "charlie", "delta",
"echo", "foxtrot", "golf", "hotel", "india", "juliet"}
for _, w := range words {
ht.Put(w, len(w))
}
fmt.Printf("Size: %d, Load: %.2f\n", ht.size, ht.loadFactor())
ht.Stats()
if val, ok := ht.Get("hotel"); ok {
fmt.Printf("Get(\"hotel\") = %d\n", val)
}
}8. Collision Strategy #6 — Cuckoo Hashing
Concept
Uses two (or more) hash functions, each mapping to a different table (or region). Each key has exactly two possible locations. On collision, the existing entry is evicted (“cuckooed”) to its alternate location, potentially triggering a chain of evictions.
textTable1: h1(key) → position in table 1
Table2: h2(key) → position in table 2
Insert key:
1. Try table1[h1(key)] — if empty, place there
2. Try table2[h2(key)] — if empty, place there
3. Evict whoever is at table1[h1(key)], place new key there
4. Place evicted key at its alternate location
5. If that causes another eviction, continue...
6. If cycle detected or max iterations reached → resize & rehashKey Properties
| Property | Value |
|---|---|
| Lookup | O(1) worst case (only 2 locations to check!) |
| Insert | O(1) amortized (can trigger chains) |
| Max load factor | ~50% (with 2 tables), ~91% (with 3+ functions) |
| Space overhead | Higher (needs lower load factor) |
Python Implementation:
import random
class CuckooHashTable:
"""Cuckoo hashing with two hash functions and two tables."""
MAX_EVICTIONS = 500 # cycle detection threshold
def __init__(self, capacity=8):
self._capacity = capacity
self._size = 0
# Two tables
self._keys1 = [None] * capacity
self._vals1 = [None] * capacity
self._keys2 = [None] * capacity
self._vals2 = [None] * capacity
# Random seeds for hash functions
self._seed1 = random.randint(0, 2**32)
self._seed2 = random.randint(0, 2**32)
def _h1(self, key) -> int:
return (hash(key) ^ self._seed1) % self._capacity
def _h2(self, key) -> int:
return (hash(key) ^ self._seed2) % self._capacity
@property
def load_factor(self):
return self._size / (2 * self._capacity)
# --- LOOKUP: O(1) worst case! ---
def get(self, key, default=None):
idx1 = self._h1(key)
if self._keys1[idx1] == key:
return self._vals1[idx1]
idx2 = self._h2(key)
if self._keys2[idx2] == key:
return self._vals2[idx2]
return default
# --- INSERT ---
def put(self, key, value):
# Check if already exists — update
idx1 = self._h1(key)
if self._keys1[idx1] == key:
self._vals1[idx1] = value
return
idx2 = self._h2(key)
if self._keys2[idx2] == key:
self._vals2[idx2] = value
return
# Insert with possible eviction chain
self._cuckoo_insert(key, value)
def _cuckoo_insert(self, key, value):
cur_key, cur_val = key, value
for _ in range(self.MAX_EVICTIONS):
# Try table 1
idx1 = self._h1(cur_key)
if self._keys1[idx1] is None:
self._keys1[idx1] = cur_key
self._vals1[idx1] = cur_val
self._size += 1
return
# Evict from table 1
self._keys1[idx1], cur_key = cur_key, self._keys1[idx1]
self._vals1[idx1], cur_val = cur_val, self._vals1[idx1]
# Try table 2 with evicted key
idx2 = self._h2(cur_key)
if self._keys2[idx2] is None:
self._keys2[idx2] = cur_key
self._vals2[idx2] = cur_val
self._size += 1
return
# Evict from table 2
self._keys2[idx2], cur_key = cur_key, self._keys2[idx2]
self._vals2[idx2], cur_val = cur_val, self._vals2[idx2]
# Cycle detected — rehash with new seeds and larger table
self._rehash()
self.put(cur_key, cur_val)
# --- DELETE: O(1) worst case ---
def delete(self, key) -> bool:
idx1 = self._h1(key)
if self._keys1[idx1] == key:
self._keys1[idx1] = None
self._vals1[idx1] = None
self._size -= 1
return True
idx2 = self._h2(key)
if self._keys2[idx2] == key:
self._keys2[idx2] = None
self._vals2[idx2] = None
self._size -= 1
return True
return False
def _rehash(self):
old_keys1, old_vals1 = self._keys1, self._vals1
old_keys2, old_vals2 = self._keys2, self._vals2
self._capacity *= 2
self._keys1 = [None] * self._capacity
self._vals1 = [None] * self._capacity
self._keys2 = [None] * self._capacity
self._vals2 = [None] * self._capacity
self._size = 0
# New hash seeds
self._seed1 = random.randint(0, 2**32)
self._seed2 = random.randint(0, 2**32)
for i in range(len(old_keys1)):
if old_keys1[i] is not None:
self.put(old_keys1[i], old_vals1[i])
for i in range(len(old_keys2)):
if old_keys2[i] is not None:
self.put(old_keys2[i], old_vals2[i])
def __len__(self):
return self._size
def __contains__(self, key):
return self.get(key, _s := object()) is not _s
def debug_print(self):
print(" Table 1:")
for i in range(self._capacity):
if self._keys1[i] is not None:
print(f" [{i}] {self._keys1[i]!r} => {self._vals1[i]!r}")
else:
print(f" [{i}] ---")
print(" Table 2:")
for i in range(self._capacity):
if self._keys2[i] is not None:
print(f" [{i}] {self._keys2[i]!r} => {self._vals2[i]!r}")
else:
print(f" [{i}] ---")
if __name__ == "__main__":
ht = CuckooHashTable(capacity=8)
words = ["red", "blue", "green", "yellow", "purple",
"orange", "pink", "black", "white", "gray"]
for w in words:
ht.put(w, w.upper())
print(f"Size: {len(ht)}, Load: {ht.load_factor:.2f}")
print(f"Capacity per table: {ht._capacity}\n")
# O(1) worst-case lookup — only checks 2 slots!
for w in ["green", "pink", "cyan"]:
result = ht.get(w, "NOT FOUND")
print(f" get({w!r}) = {result}")
ht.debug_print()9. Load Factor, Resizing & Amortized Analysis
Load Factor Thresholds by Strategy
| Strategy | Typical Max α | Why |
|---|---|---|
| Separate Chaining | 0.75 – 1.0 | Chains grow linearly; α > 1 is fine |
| Linear Probing | 0.5 – 0.7 | Clustering degrades rapidly past 0.7 |
| Quadratic Probing | 0.5 | Must stay ≤ 0.5 for guaranteed slot finding |
| Double Hashing | 0.6 – 0.7 | Better than linear, less clustering |
| Robin Hood | 0.7 – 0.9 | Equalized displacements handle high load |
| Cuckoo (2 funcs) | 0.5 | Per-table; ~0.5 total capacity utilization |
Resize Strategy: Amortized O(1)
When the load factor exceeds the threshold:
- Allocate a new array of 2× capacity
- Rehash every existing entry (O(n) operation)
- Because this only happens after n/2 insertions, the amortized cost per insertion is O(1)
textInsertions: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
↑ ↑
resize(8→16) resize(16→32)
cost: 8 cost: 16
Total cost for 17 inserts: 17 + 8 + 16 = 41 → 41/17 ≈ 2.4 = O(1) amortizedGrowth Factor Analysis
| Growth Factor | Space Waste | Resize Frequency | Used By |
|---|---|---|---|
| 2× | Up to 50% unused | Less frequent | Most implementations |
| 1.5× | Up to 33% unused | More frequent | Facebook folly |
| φ (≈1.618) | Good balance | Moderate | Some C++ libs |
10. How Real Languages Do It
CPython dict (Python 3.6+)
Python’s dictionary is one of the most heavily optimized hash tables in existence.
Strategy: Open addressing with perturbed probing (a custom probe sequence)
C Code:
// CPython's probe sequence (simplified from dictobject.c)
// j = initial index
// perturb = full hash value
while (1) {
if (slot_is_empty_or_matches)
return slot;
perturb >>= PERTURB_SHIFT; // PERTURB_SHIFT = 5
j = (5 * j + perturb + 1) % capacity;
}Key design decisions:
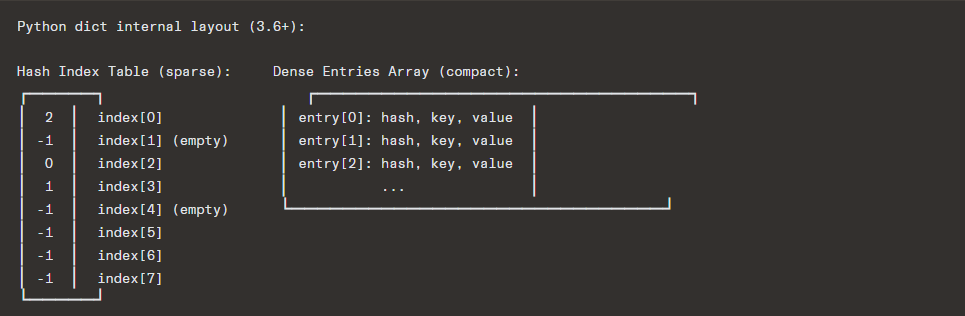
- Compact dict (since 3.6): Separates a hash index table (sparse, small entries) from a dense entries array (ordered). This gives insertion-ordered iteration and saves ~25% memory.
- Table capacity is always a power of 2
- Load factor threshold: 2/3 ≈ 0.667
- Uses SipHash for strings (DoS protection)
- Growth: 2× when small, capacity based on used + growth estimate
Go map
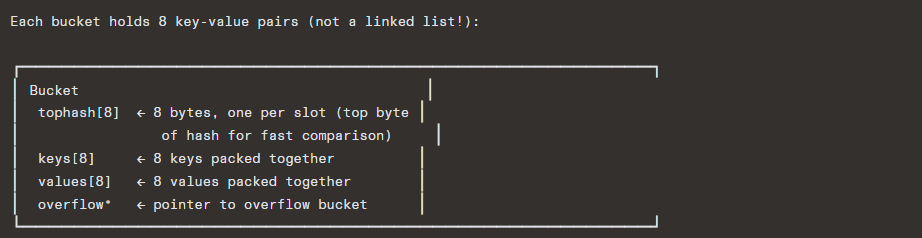
Strategy: Separate chaining with buckets (a highly optimized hybrid)
Go’s map uses a unique approach:
Key design decisions:
- Bucket size = 8 entries (fits cache line well)
- Top-hash byte stored per entry: fast rejection without comparing full keys
- Load factor threshold: 6.5 entries per bucket (α ≈ 6.5)
- Incremental resizing: doesn’t rehash everything at once; gradually evacuates old buckets during subsequent operations
- Map capacity always power of 2 number of buckets
- Iteration order is intentionally randomized (starting bucket is random)
textLookup process:
1. hash(key) → lower bits select bucket, top 8 bits = tophash
2. Compare tophash[i] for each of 8 slots (SIMD-friendly!)
3. Only if tophash matches, compare full key
4. If not found, follow overflow pointerRust HashMap (hashbrown / SwissTable)
Strategy: Open addressing with SIMD-accelerated probing (Swiss Table design from Google)
This is the most modern and sophisticated design of the three.
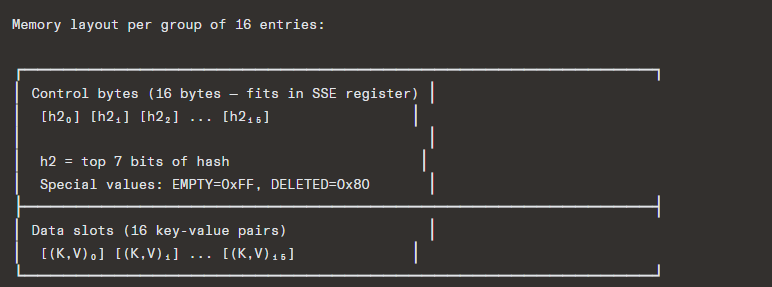
Key design decisions:
- Groups of 16 slots with 16 control bytes (one byte per slot)
- Control bytes hold the top 7 bits of the hash (h2) or a sentinel
- Probing uses SIMD: load all 16 control bytes into a 128-bit register, compare against h2 with a single instruction, get a bitmask of matching slots
- This means checking 16 slots simultaneously in 1 CPU instruction!
- Uses SipHash 1-3 by default (DoS resistant, but configurable)
- Load factor: grows at 7/8 = 87.5% (can afford high load due to SIMD)
- Triangular probing over groups: group sequence = 0, 1, 3, 6, 10, … (triangular numbers)

Summary Comparison

11. Performance Comparison
Theoretical Average-Case Probe Counts
For a table with load factor α:
| Strategy | Successful Search | Unsuccessful Search |
|---|---|---|
| Separate Chaining | 1 + α/2 | 1 + α |
| Linear Probing | ½(1 + 1/(1-α)) | ½(1 + (1/(1-α))²) |
| Quadratic Probing | -ln(1-α)/α | 1/(1-α) – α + ln(1-α) |
| Double Hashing | -ln(1-α)/α | 1/(1-α) |
| Robin Hood | Same as linear avg | O(log n) worst case |
At α = 0.7
| Strategy | Avg Probes (Hit) | Avg Probes (Miss) |
|---|---|---|
| Chaining | 1.35 | 1.70 |
| Linear Probing | 1.72 | 6.06 |
| Double Hashing | 1.53 | 3.33 |
| Robin Hood | 1.72 (avg) | max ≈ O(log n) |
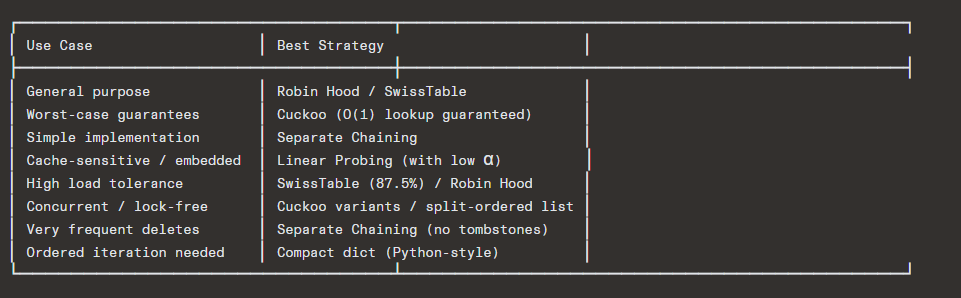
Cache Behavior
This is often the dominant factor in real-world performance:
textSeparate Chaining:
❌ Pointer chasing → random memory access → cache misses
❌ Nodes scattered across heap
Linear/Quadratic/Robin Hood Probing:
✅ Sequential memory access → prefetcher friendly
✅ All data in contiguous array
SwissTable:
✅✅ Control bytes are tiny (16 bytes per group, fits in cache line)
✅✅ SIMD operates on register-width data
✅✅ Only touches data slots on actual matchFinal Takeaway
The evolution of hash tables tells a story of trading complexity for performance:

Modern hash tables (SwissTable/hashbrown, Go’s bucket map, Python’s compact dict) are co-designed with CPU architecture — exploiting cache lines, SIMD instructions, and branch prediction to achieve performance that the Big-O notation alone cannot capture.