Every time you load a webpage, send an email, transfer a file, or SSH into a remote server, the Transmission Control Protocol (TCP) is silently doing the heavy lifting beneath the surface. It is the backbone of reliable communication on the Internet — yet most developers and engineers interact with it only through high-level socket APIs, never peeling back the layers to understand what actually happens on the wire and inside the kernel, and how beautiful it is.
TCP is deceptively simple on the surface: it takes a stream of bytes from an application, delivers them reliably and in order to the other end, and handles all the messy realities of packet loss, network congestion, reordering, and flow control in between. But behind that clean abstraction lies over four decades of engineering — a state machine with 11 states, multiple retransmission strategies, a family of congestion control algorithms that are still actively researched today, and a header design that has been carefully extended through options while maintaining backward compatibility with implementations from the 1980s.
Whether you’re a backend engineer debugging latency spikes in production, a network engineer tuning kernel parameters for high-throughput servers, a security researcher analyzing TCP-based attacks, or a student preparing for a systems interview — understanding TCP at the protocol level gives you a powerful mental model for reasoning about networked systems.
In this post, we go far beyond the textbook three-way handshake. We’ll walk through the byte-level segment structure, dissect how sequence numbers, acknowledgments, and sliding windows actually work, explore the evolution of congestion control from Tahoe to BBR, examine the TCP state machine transition by transition, cover modern extensions like MPTCP, TCP Fast Open, RACK, and TLP, and look at how all of this is implemented inside the Linux kernel. By the end, you’ll have a comprehensive, reference-grade understanding of TCP internals.
Table of Contents
- Introduction & Historical Context
- TCP in the Protocol Stack
- TCP Segment Structure
- Connection Lifecycle
- Reliable Data Transfer Mechanisms
- Flow Control
- Congestion Control
- TCP Timers
- TCP Options
- TCP State Machine
- Advanced Topics & Modern Extensions
- Security Considerations
- TCP vs. Other Transport Protocols
- Implementation Details (Kernel Perspective)
- Conclusion
1. Introduction & Historical Context
What is TCP?
The Transmission Control Protocol (TCP) is a connection-oriented, reliable, byte-stream transport-layer protocol defined primarily in RFC 793 (1981), with numerous subsequent RFCs refining and extending it. It is one of the two original core protocols of the Internet Protocol Suite (the other being UDP), and it provides the reliability layer upon which the vast majority of Internet applications — HTTP, SMTP, FTP, SSH, TLS — are built.
Historical Evolution
| Year | Milestone |
|---|---|
| 1974 | Vint Cerf & Bob Kahn publish “A Protocol for Packet Network Intercommunication” — TCP and IP were originally a single protocol |
| 1978 | TCP split into TCP (transport) and IP (network) — TCP/IP model born |
| 1981 | RFC 793 — the foundational TCP specification |
| 1983 | ARPANET switches from NCP to TCP/IP (“Flag Day”, January 1) |
| 1988 | Van Jacobson introduces congestion control algorithms (Tahoe) after “congestion collapse” events |
| 1990 | TCP Reno — Fast Recovery added |
| 1996 | RFC 2018 — Selective Acknowledgments (SACK) |
| 2004 | RFC 3782 — NewReno refinements |
| 2006 | CUBIC congestion control (default in Linux) |
| 2013 | RFC 6824 — Multipath TCP (MPTCP) |
| 2016 | BBR congestion control by Google |
| 2022 | RFC 9293 — consolidates and obsoletes RFC 793 and multiple related RFCs |
Design Philosophy
TCP was designed around several key principles:
- End-to-end principle: Intelligence at the endpoints, dumb network core
- Robustness principle (Postel’s Law): “Be conservative in what you send, be liberal in what you accept”
- Layered architecture: TCP is agnostic to what IP does below and what applications do above
2. TCP in the Protocol Stack
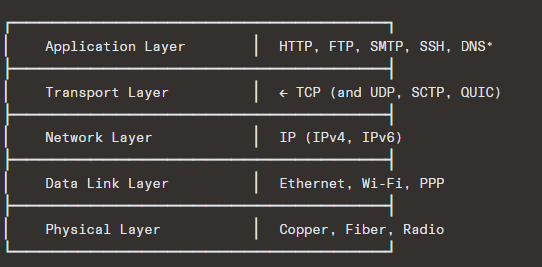
TCP sits between the application layer and the network layer. It takes a byte stream from the application, segments it, hands segments to IP, and on the receiving end, reassembles them back into an ordered byte stream.
Key Abstractions TCP Provides Over IP

3. TCP Segment Structure
3.1 Header Format
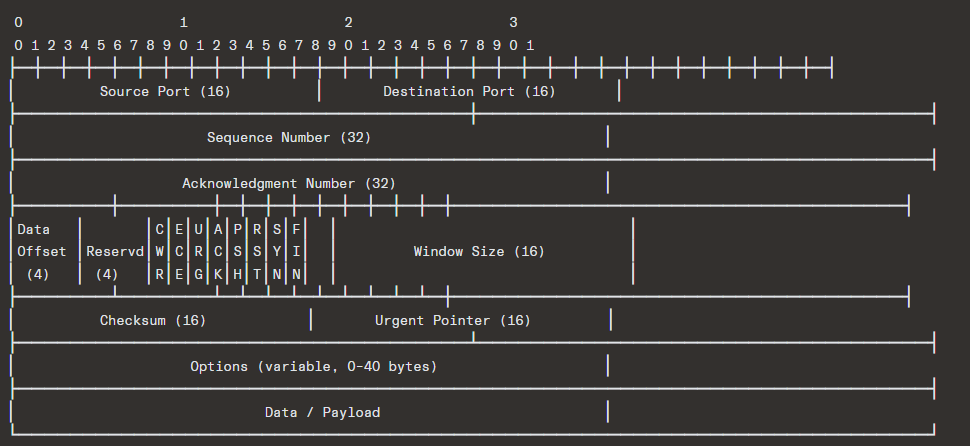
Minimum header size: 20 bytes (no options)
Maximum header size: 60 bytes (with options)
3.2 Field-by-Field Deep Dive
Source Port & Destination Port (16 bits each)
- Together with source/destination IP addresses, they form a 4-tuple that uniquely identifies a TCP connection (socket pair).
- Well-known ports: 0–1023; Registered: 1024–49151; Dynamic/Ephemeral: 49152–65535.
- The ephemeral port range is OS-dependent (Linux default: 32768–60999).
Sequence Number (32 bits)
- Identifies the byte position within the stream of the first data byte in this segment.
- If SYN is set, this is the Initial Sequence Number (ISN), and the first data byte is ISN+1.
- 32-bit space = 4,294,967,296 bytes before wrapping — at 10 Gbps, this wraps in ~3.4 seconds, creating challenges addressed by PAWS (Protection Against Wrapped Sequences).
Acknowledgment Number (32 bits)
- The next sequence number the sender of the ACK expects to receive.
- This is a cumulative acknowledgment: it implicitly acknowledges all bytes up to (but not including) this number.
- Only meaningful when the ACK flag is set (which is virtually always after the SYN).
Data Offset (4 bits)
- Specifies the size of the TCP header in 32-bit words.
- Minimum value: 5 (= 20 bytes); Maximum value: 15 (= 60 bytes).
- Tells the receiver where the data begins.
Reserved (4 bits)
- Originally 6 bits (reduced as CWR and ECE flags were added).
- Must be set to zero.
Flags (Control Bits) — 8 bits

Detailed Flag Semantics:
- SYN: Consumes one sequence number. Used in the three-way handshake. Carries initial parameters (MSS, window scale, SACK-permitted, timestamps, etc.) as options.
- FIN: Also consumes one sequence number. Indicates the sender’s byte stream has ended. The connection is half-closed — the other side can still send data.
- RST: Immediately terminates the connection. No ACK is expected or required. Common triggers: connection to a closed port, aborting a connection, responding to invalid segments.
- PSH: An advisory flag telling the receiving TCP stack to deliver data to the application without waiting for buffer fill. Many implementations set this on every segment containing data.
- URG: Historically used for “out-of-band” data (e.g., Telnet interrupt). Largely deprecated; RFC 6093 discourages its use.
- ACK: Set on virtually every segment after the initial SYN. A segment with only ACK (no data) is sometimes called a “bare ACK” or “pure ACK.”
Window Size (16 bits)
- The number of bytes the sender of this segment is willing to accept (the receive window, rwnd).
- With the Window Scale option, this is a base value that gets left-shifted, allowing windows up to 2^30 = 1 GiB.
Checksum (16 bits)
- Covers the pseudo-header (source IP, destination IP, protocol number, TCP length), the TCP header, and the data.
- Computed as the 16-bit one’s complement of the one’s complement sum of all 16-bit words.
- Mandatory in TCP (unlike UDP where it’s optional in IPv4).
- Known to be weak — does not detect all error patterns. Modern NICs often perform checksum offloading.
Urgent Pointer (16 bits)
- An offset from the sequence number indicating the last byte of urgent data.
- Only meaningful when URG is set.
- Largely obsolete.
Options (variable)
- Covered in detail in Section 9.
4. Connection Lifecycle
4.1 Three-Way Handshake (Connection Establishment)
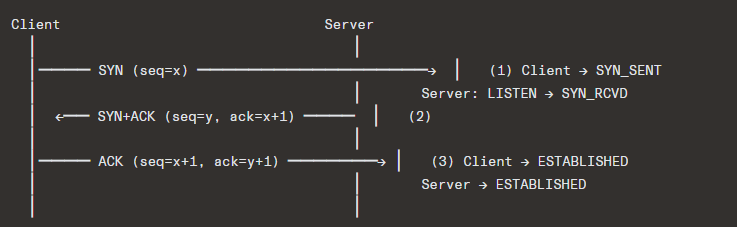
Why Three Ways?
The three-way handshake solves three problems:
- Both sides agree to communicate (mutual consent)
- Both sides synchronize sequence numbers (x and y are both communicated and acknowledged)
- Prevents old duplicate connection initiations from being accepted (the ISN validation)
Initial Sequence Number (ISN) Selection:
- ISNs must be unpredictable to prevent TCP sequence prediction attacks (RFC 6528).
- Modern implementations use a combination of:
- A secret key
- Source/destination IP and port
- A clock-based component
- Cryptographic hash (e.g., MD5, SipHash)
- Linux uses
SipHashover the 4-tuple plus a secret, plus a time-based component.
SYN Queue and Accept Queue:
On the server side, the kernel maintains two queues:

- SYN Queue: Stores connections in SYN_RCVD state. Size governed by
tcp_max_syn_backlog. - Accept Queue: Stores fully established connections waiting for
accept(). Size governed bymin(backlog, somaxconn).
SYN Cookies (RFC 4987):
When the SYN queue is full, Linux can use SYN cookies — the server encodes connection state into the ISN of the SYN-ACK, avoiding the need to store any state. The ISN encodes:
- A timestamp (5 bits, granularity ~64 seconds)
- MSS index (3 bits)
- A cryptographic hash of the 4-tuple and the timestamp
Trade-off: TCP options from the SYN (like window scaling, SACK, timestamps) are lost since no state is stored.
4.2 Simultaneous Open
Both sides can simultaneously send SYN to each other, resulting in a four-way handshake:
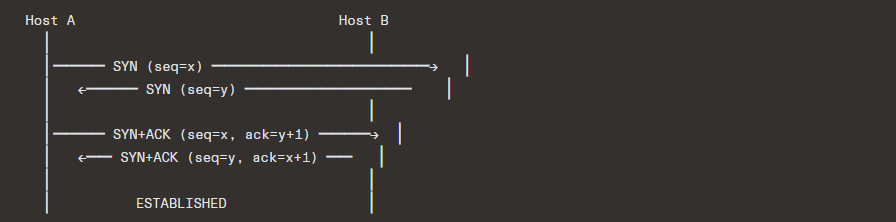
This is rare but fully supported by the TCP specification.
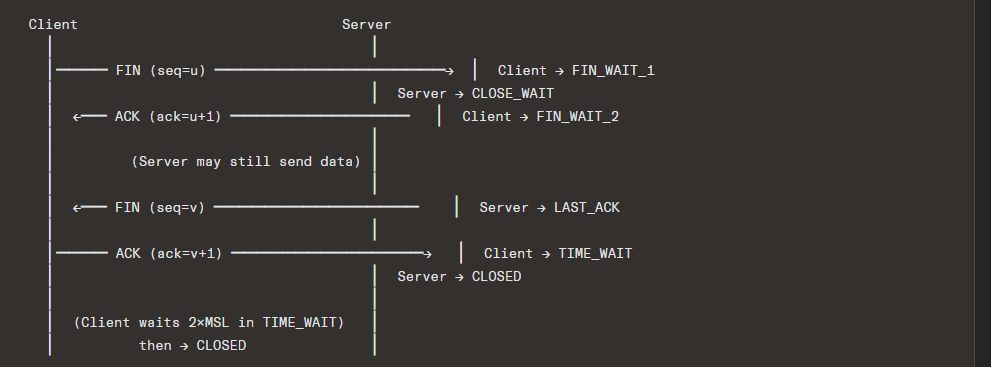
4.3 Connection Termination
Normal Close: Four-Way Handshake
Three-Way Close (Piggyback)
If the server has no more data, it can combine its ACK and FIN:
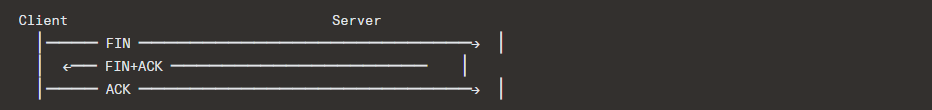
Half-Close
TCP supports half-duplex close: one side sends FIN (indicating it’s done sending), but the other side can continue sending data. This is used by applications like HTTP/1.0 where the server sends FIN after the response body, but the client’s request was already complete.
4.4 TIME_WAIT State
Duration: 2 × MSL (Maximum Segment Lifetime). RFC 793 defines MSL as 2 minutes, so TIME_WAIT = 4 minutes. Linux uses 60 seconds (hardcoded as TCP_TIMEWAIT_LEN).
Why TIME_WAIT exists:
- Reliable termination: If the final ACK is lost, the peer will retransmit its FIN. The TIME_WAIT state ensures the endpoint can still respond.
- Prevent old duplicates: Ensures that delayed segments from this connection don’t get misinterpreted as belonging to a new connection using the same 4-tuple.
TIME_WAIT Implications:
- On busy servers, thousands of sockets in TIME_WAIT can exhaust ephemeral ports or consume memory.
- Linux mitigations:
tcp_tw_reuse: Allows reusing TIME_WAIT sockets for outgoing connections if the timestamp is newer.SO_REUSEADDR/SO_REUSEPORT: Allow binding to addresses/ports already in use.tcp_max_tw_buckets: Limits total TIME_WAIT sockets.tcp_tw_recycle(removed in Linux 4.12 — it was broken behind NATs).
4.5 Reset (RST)
RST immediately tears down a connection. Common scenarios:
| Scenario | Description |
|---|---|
| Connection to closed port | SYN arrives at a port with no listener |
| Aborting a connection | Application calls close() with SO_LINGER set to 0 |
| Half-open connection detection | One side crashed and rebooted; the other side sends data and gets RST |
| Firewall intervention | Middlebox injects RST to terminate connections |
RST attacks: An attacker who can guess the sequence number in the receive window can inject an RST and terminate a connection. Mitigated by:
- Randomized ISNs
- RFC 5961: Requires RST sequence number to match exactly
rcv.nxt, or else send a “challenge ACK”
5. Reliable Data Transfer Mechanisms
5.1 Sequence Numbers and Acknowledgments
TCP provides reliability through a combination of:
- Sequence numbers: Every byte of data is numbered.
- Cumulative ACKs: The ACK number indicates “I’ve received everything up to this byte.”
- Retransmission: Lost segments are retransmitted.
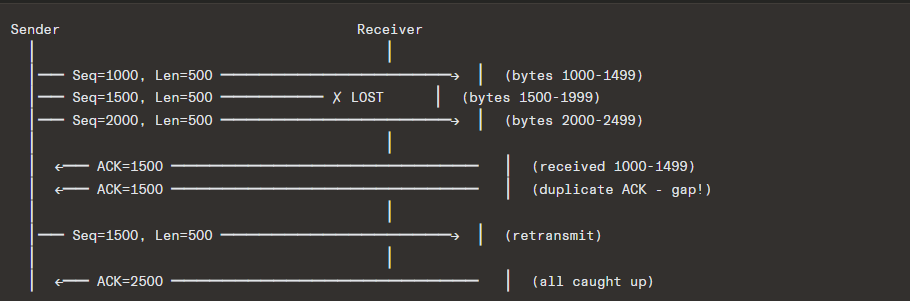
5.2 Retransmission Strategies
Timeout-Based Retransmission (RTO)
If an ACK is not received within the Retransmission Timeout (RTO), the segment is retransmitted.
RTO Calculation (RFC 6298):

Exponential Backoff: After each timeout, RTO is doubled (capped at an upper bound). This is Karn’s algorithm — retransmitted segments are not used to update RTT estimates (ambiguity problem).
Fast Retransmit (RFC 5681)
Instead of waiting for a timeout, the sender retransmits upon receiving 3 duplicate ACKs (4 ACKs for the same sequence number total):

This is much faster than waiting for RTO, which can be hundreds of milliseconds to seconds.
Selective Acknowledgment (SACK) — RFC 2018
Cumulative ACKs are wasteful when there are multiple losses in a window. SACK allows the receiver to inform the sender about non-contiguous blocks that have been received:

This tells the sender: “I’m missing 1500-1999 and 2500-2999, but I have the rest.”
SACK internals:
- Negotiated during the handshake via the SACK-Permitted option.
- SACK blocks are carried in the SACK option (kind=5) in ACK segments.
- Up to 4 SACK blocks per segment (limited by option space, especially if timestamps are used — then only 3 blocks).
- The sender maintains a scoreboard tracking which bytes have been SACKed, allowing it to retransmit only truly lost segments.
Duplicate SACK (D-SACK) — RFC 2883
Extends SACK to indicate that a segment was received more than once. This helps the sender distinguish between:
- Genuine packet loss
- Packet reordering
- ACK loss
- Spurious retransmissions
5.3 Retransmission Ambiguity
When a retransmitted segment is ACKed, the sender can’t tell if the ACK is for the original or the retransmission. Solutions:
- Karn’s Algorithm: Don’t update RTT estimates on retransmitted segments.
- TCP Timestamps (RFC 7323): Each segment carries a timestamp; the ACK echoes it back, disambiguating RTT measurement.
6. Flow Control
6.1 Sliding Window Mechanism
TCP uses a sliding window protocol for flow control. The receiver advertises a receive window (rwnd) — the number of bytes it’s willing to accept.

Key variables (sender):
SND.UNA— oldest unacknowledged byteSND.NXT— next byte to sendSND.WND— send window (= receiver’s advertised rwnd)- Usable window =
SND.UNA + SND.WND - SND.NXT
Key variables (receiver):
RCV.NXT— next expected byteRCV.WND— receive window (advertised to sender)
6.2 Zero Window and Window Probes
When the receiver’s buffer is full, it advertises rwnd = 0. The sender must stop sending data. To recover:
- The sender starts a persist timer.
- When it fires, the sender sends a window probe — a segment with 1 byte of data (or zero-length).
- The receiver responds with an ACK containing the current window size.
- If still zero, the sender backs off exponentially and probes again.
This prevents deadlock: without probes, a window update from the receiver could be lost, and both sides would wait forever.
6.3 Silly Window Syndrome (SWS)
Problem: If the receiver opens the window by tiny amounts, and the sender sends tiny segments, efficiency plummets (high overhead-to-data ratio).
Solutions:
Receiver side (Clark’s algorithm / RFC 1122):
- Don’t advertise a window increase until the window is at least
min(MSS, buffer_size/2).
Sender side (Nagle’s algorithm — RFC 896):

Nagle’s algorithm reduces the number of small segments (“tinygrams”) on the network. However, it can introduce latency for interactive applications (e.g., SSH, gaming), so it can be disabled with TCP_NODELAY.
Interaction with Delayed ACKs: Nagle + delayed ACKs can cause pathological 200ms delays. When an application does two small writes followed by a read (common in request-response protocols), Nagle holds the second write until the first is ACKed, and delayed ACK holds the ACK for up to 200ms. Solution: TCP_NODELAY, TCP_CORK, or using vectored I/O (writev).
6.4 Window Scaling — RFC 7323
The 16-bit window field limits the advertised window to 65,535 bytes. This is insufficient for high-bandwidth, high-latency paths (the bandwidth-delay product):

A 64 KB window would only allow ~5.2 Mbps throughput on this path.
Window Scale option: Negotiated in the SYN/SYN-ACK, specifies a shift count (0–14):

7. Congestion Control
Congestion control is arguably the most complex and researched aspect of TCP. It controls the sending rate to avoid overwhelming the network.
7.1 Core Concept: The Congestion Window
The effective sending window is:

Where:
cwnd= congestion window (sender’s estimate of network capacity)rwnd= receive window (receiver’s buffer capacity)
7.2 Classic Algorithms (TCP Reno family)
Slow Start (RFC 5681)
Despite the name, slow start is exponential growth:

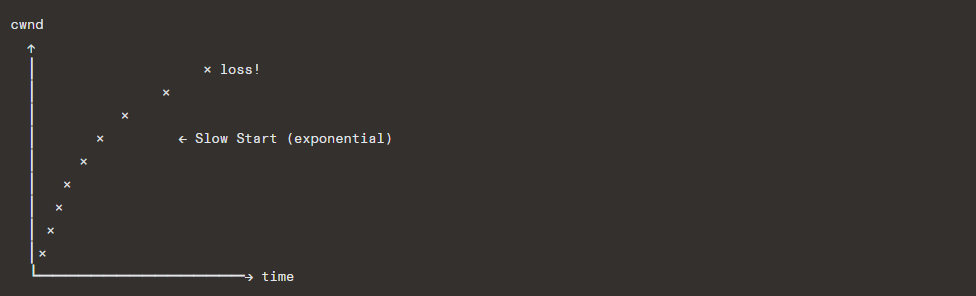
Congestion Avoidance
Linear growth (additive increase):

This is the AIMD (Additive Increase, Multiplicative Decrease) phase.
Loss Detection and Response
TCP Tahoe (1988):
- On any loss (timeout or 3 dup ACKs):
ssthresh = cwnd / 2cwnd = 1 MSS- Enter Slow Start
TCP Reno (1990):
- On timeout:
- Same as Tahoe
- On 3 duplicate ACKs (Fast Retransmit + Fast Recovery):
ssthresh = cwnd / 2cwnd = ssthresh + 3 MSS(inflate for the 3 dup ACKs)- For each additional dup ACK:
cwnd += MSS - When new ACK arrives:
cwnd = ssthresh(deflate), enter Congestion Avoidance
TCP NewReno (RFC 3782):
- Fixes Reno’s behavior with multiple losses in a single window.
- Stays in Fast Recovery until all data outstanding at the time of loss detection is ACKed (tracks the “recovery point”).
- Handles partial ACKs (ACKs that advance SND.UNA but don’t cover the recovery point) by retransmitting the next suspected lost segment.
7.3 SACK-based Loss Recovery
With SACK, the sender maintains a scoreboard and can precisely retransmit only lost segments:

This is far more efficient than Reno/NewReno for multiple losses.
7.4 Proportional Rate Reduction (PRR) — RFC 6937
Modern Linux uses PRR instead of classic Fast Recovery. PRR smoothly reduces cwnd during recovery rather than the sharp halving and re-inflation of Reno:

7.5 CUBIC — RFC 8312
Default congestion control in Linux since 2.6.19 (2006).
CUBIC uses a cubic function of time since the last congestion event to determine cwnd:
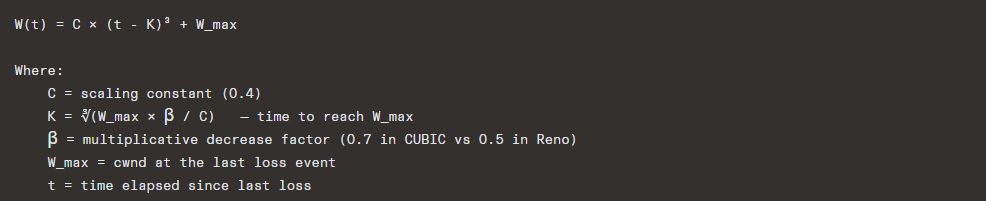
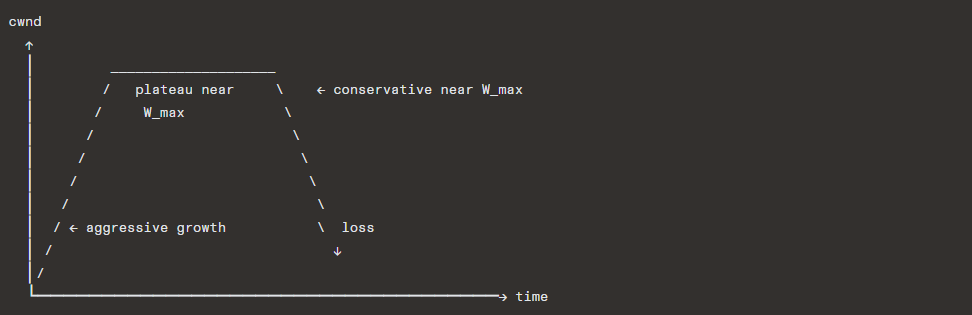
Key properties:
- Window-based, not rate-based
- RTT-fairness: The cubic function is based on elapsed time, not RTTs, making it fairer across connections with different RTTs (unlike Reno where high-RTT connections grow slower)
- Aggressive growth far from W_max, conservative near it (the flat part of the cubic curve provides stability)
- TCP-friendly region: Falls back to Reno-like behavior when CUBIC would be less aggressive
7.6 BBR (Bottleneck Bandwidth and RTT) — Google, 2016
BBR represents a paradigm shift from loss-based to model-based congestion control.
Core philosophy: Loss is not a reliable signal of congestion. In networks with deep buffers, loss-based algorithms fill buffers, causing bufferbloat (high latency). BBR instead estimates:
- BtlBw — bottleneck bandwidth (maximum delivery rate)
- RTprop — round-trip propagation delay (minimum RTT)
The optimal operating point is:

This is the Kleinrock optimal — maximum throughput with minimum delay.
BBR State Machine:
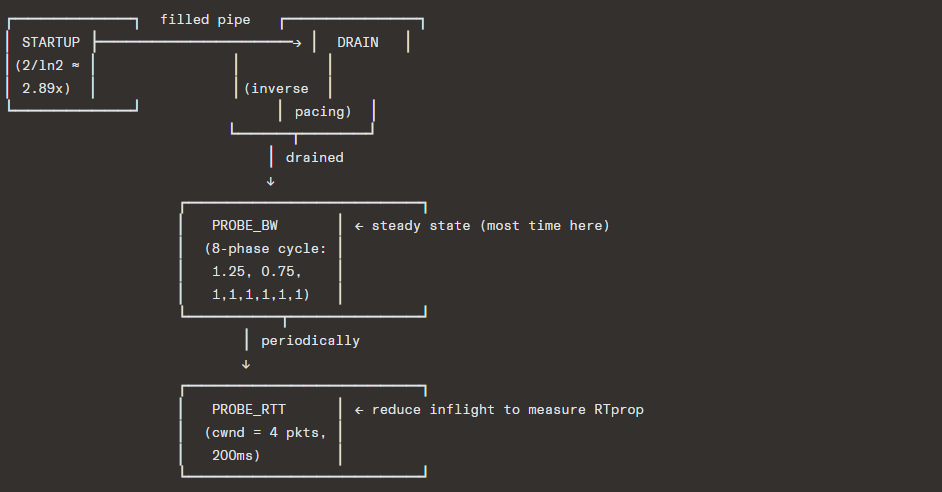
BBR pacing: Unlike window-based algorithms, BBR controls the rate at which packets are sent using pacing (spacing packets evenly), reducing burstiness.
BBR versions:
- BBRv1: Initial version, known for unfairness to loss-based flows and intra-protocol unfairness
- BBRv2: Addresses fairness and excessive loss issues; uses ECN signals, pacing improvements
- BBRv3: Further refinements (still evolving as of 2024)
7.7 ECN (Explicit Congestion Notification) — RFC 3168
Instead of dropping packets to signal congestion, ECN-capable routers can mark packets:
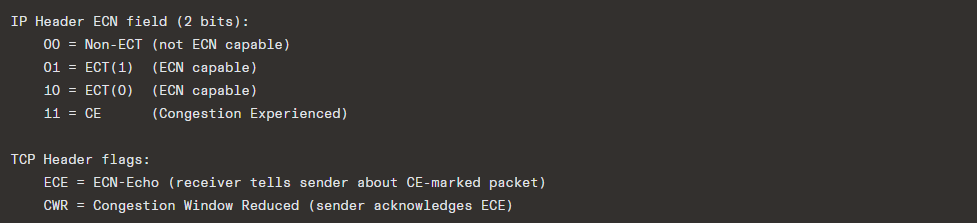
Flow:
- Sender sets ECT(0) or ECT(1) in IP packets
- Congested router changes ECT → CE (instead of dropping)
- Receiver sees CE, sets ECE flag in subsequent ACKs
- Sender sees ECE, reduces cwnd, sets CWR flag
- Receiver sees CWR, stops sending ECE
Benefits: Avoids packet loss entirely; enables faster congestion response (especially with algorithms like DCTCP that react proportionally to the fraction of marked packets).
7.8 Summary of Congestion Control Algorithms
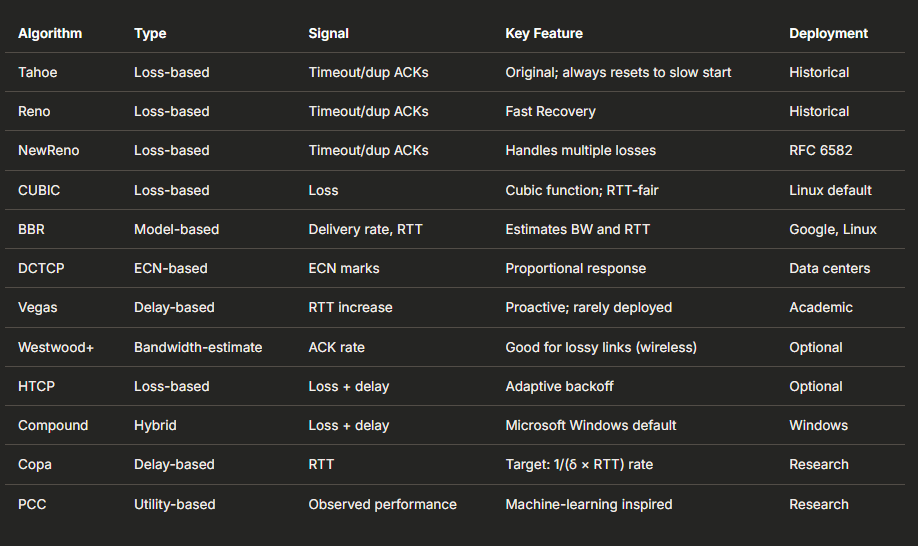
8. TCP Timers
TCP maintains several timers per connection:
8.1 Retransmission Timer (RTO Timer)
- Set when a segment is sent and no ACK is pending.
- Fires when an ACK hasn’t arrived within the RTO.
- On expiry: retransmit the oldest unacknowledged segment, double the RTO (exponential backoff).
- Cleared when all outstanding data is acknowledged.
8.2 Persist Timer
- Set when the receiver advertises
rwnd = 0. - Fires to trigger a window probe.
- Exponential backoff, but never gives up (connections can survive zero-window indefinitely).
8.3 Keepalive Timer
- Optional mechanism to detect dead connections (RFC 1122).
- Default: After 2 hours of inactivity, send a keepalive probe.
- If no response after
tcp_keepalive_probes(default 9) probes senttcp_keepalive_intvl(default 75 seconds) apart, the connection is considered dead. - Linux parameters:

- Total timeout = 7200 + 75 × 9 = 7875 seconds ≈ 2.2 hours
8.4 TIME_WAIT Timer (2MSL Timer)
- Duration: 2 × MSL (60 seconds on Linux).
- Ensures the connection 4-tuple is not reused too soon.
8.5 Delayed ACK Timer
- TCP delays ACKs by up to 40ms (Linux) or 200ms (RFC recommendation) to piggyback ACKs on data going the other direction.
- An ACK is sent immediately if:
- Two full-size segments received (every-other-segment ACK)
- An out-of-order segment arrives
- The delayed ACK timer expires
8.6 FIN_WAIT_2 Timer
- In
FIN_WAIT_2state, if the connection is orphaned (closed by application), Linux sets a timer (tcp_fin_timeout, default 60 seconds) to prevent indefinite wait.
9. TCP Options
TCP options provide extensibility. They are carried in the TCP header between the fixed 20-byte header and the data.

Key Options
| Kind | Length | Name | Description | RFC |
|---|---|---|---|---|
| 0 | 1 | End of Options | Marks end of options list | 793 |
| 1 | 1 | NOP | Padding/alignment | 793 |
| 2 | 4 | MSS | Maximum Segment Size | 793 |
| 3 | 3 | Window Scale | Window scaling factor | 7323 |
| 4 | 2 | SACK Permitted | Enables SACK | 2018 |
| 5 | var | SACK | Selective ACK blocks | 2018 |
| 8 | 10 | Timestamps | TSval and TSecr | 7323 |
| 14 | 3 | TCP-AO | Authentication Option | 5925 |
| 28 | var | User Timeout | UTO | 5482 |
| 29 | var | TCP-AO | Authentication (updated) | 5925 |
| 30 | var | Multipath TCP | MPTCP signaling | 6824 |
| 34 | var | TCP Fast Open | TFO cookie | 7413 |
| 253-254 | var | Experimental | RFC 6994 | — |
9.1 MSS (Maximum Segment Size) — Kind 2
- Sent only in SYN segments.
- Declares the largest segment the sender is willing to receive.
- Does NOT include IP or TCP headers.
- Typical values:
- Ethernet: 1460 bytes (1500 MTU – 20 IP – 20 TCP)
- IPv6: 1440 bytes (1500 – 40 IPv6 – 20 TCP)
- Loopback: 65495 bytes
- If not present, defaults to 536 bytes.
- Path MTU Discovery (RFC 1191) can further constrain the effective MSS.
9.2 Timestamps — Kind 8

- TSval (Timestamp Value): Sender’s current timestamp clock.
- TSecr (Timestamp Echo Reply): Echoes the most recent TSval received from the peer.
Uses:
- RTTM (Round-Trip Time Measurement): More accurate than ACK-based RTT estimation, works with SACK.
- PAWS (Protection Against Wrapped Sequences): Detects old duplicate segments even after sequence numbers wrap. Uses timestamps as a 32-bit extension of the sequence space.
9.3 TCP Fast Open (TFO) — RFC 7413
Allows data to be carried in the SYN packet of a connection, saving one RTT:
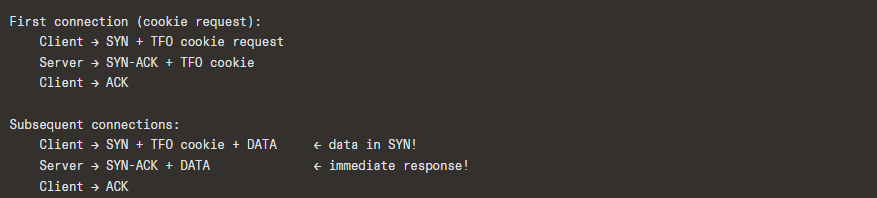
Security: The cookie (generated by the server using a secret key) prevents blind SYN+data flooding from spoofed IPs.
Limitations: Application must be idempotent for the SYN data (since it might be replayed). Not universally deployed due to middlebox interference.
10. TCP State Machine
The TCP state machine has 11 states:
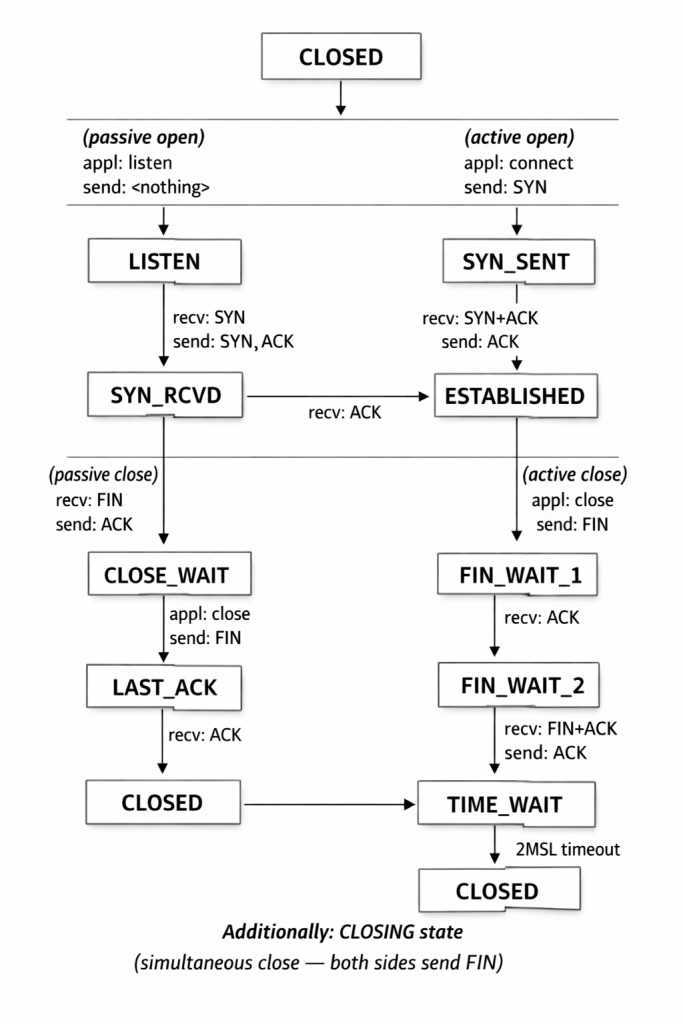
State Descriptions
| State | Description |
|---|---|
CLOSED | No connection exists |
LISTEN | Server waiting for incoming SYN |
SYN_SENT | Client has sent SYN, awaiting SYN-ACK |
SYN_RCVD | Server has received SYN, sent SYN-ACK, awaiting ACK |
ESTABLISHED | Connection is open; data transfer in progress |
FIN_WAIT_1 | Application has closed; FIN sent, awaiting ACK |
FIN_WAIT_2 | FIN has been ACKed; awaiting peer’s FIN |
CLOSE_WAIT | Received FIN from peer; waiting for application to close |
CLOSING | Both sides sent FIN simultaneously; awaiting ACK |
LAST_ACK | Sent FIN after receiving peer’s FIN; awaiting final ACK |
TIME_WAIT | Waiting 2×MSL before fully closing |
Monitoring states: netstat -ant, ss -ant in Linux.
11. Advanced Topics & Modern Extensions
11.1 Multipath TCP (MPTCP) — RFC 6824 / RFC 8684
MPTCP allows a single TCP connection to use multiple network paths simultaneously:

Key Features:
- Backward compatible: Falls back to regular TCP if middleboxes interfere
- Subflow management: Add/remove paths dynamically
- Coupled congestion control: Ensures MPTCP doesn’t take unfair share at shared bottlenecks
- Used by: Apple (iOS Siri since iOS 7, all iOS/macOS apps can use it), Linux kernel (upstream since 5.6)
11.2 TCP in Data Centers
Data center TCP has unique requirements: very low latency, high bandwidth, shallow buffers.
DCTCP (Data Center TCP) — RFC 8257:
- Uses ECN marks proportionally: Instead of halving cwnd on any ECN mark (like classic ECN), DCTCP reduces cwnd proportionally to the fraction of marked packets.
- Maintains very low queue occupancy.
cwnd = cwnd × (1 - α/2)whereα ∈ [0,1]is the moving average of the fraction of marked packets.
Other data center innovations:
- NDP (NDP at SIGCOMM 2017): Receiver-driven flow control
- HPCC (High Precision Congestion Control): Uses in-network telemetry (INT)
- Swift (Google): Delay-based, fabric-aware congestion control
11.3 TCP over Wireless/Lossy Links
TCP’s assumption that packet loss = congestion is wrong for wireless links, where random bit errors cause loss.
Approaches:
- Freeze-TCP: Receiver proactively advertises zero window before handoff
- Westwood+: Uses ACK rate to estimate bandwidth, avoids aggressive cwnd reduction on random loss
- Link-layer ARQ: Retransmit at the link layer (802.11 retransmissions) before TCP notices
- Split TCP: Performance-enhancing proxies (PEPs) terminate TCP at the wireless boundary
11.4 TCP Offloading
Modern NICs can offload TCP processing:
| Offload Type | Description |
|---|---|
| Checksum Offload | NIC computes/verifies TCP checksum |
| TSO (TCP Segmentation Offload) | Kernel sends large (up to 64KB) segments; NIC splits into MSS-sized |
| GRO (Generic Receive Offload) | NIC/driver aggregates multiple segments into one large segment for kernel |
| LRO (Large Receive Offload) | Hardware-based aggregation (less flexible than GRO) |
| TOE (TCP Offload Engine) | Full TCP stack on the NIC — controversial; limited adoption |
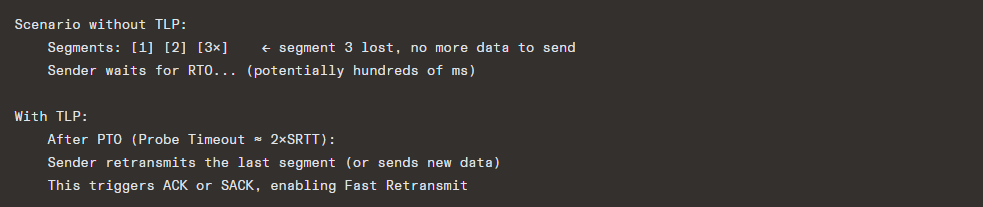
11.5 Tail Loss Probe (TLP) — RFC 8985
TLP addresses the problem of tail losses — losses at the end of a transaction that can only be recovered via RTO (since no further data triggers dup ACKs):
11.6 RACK (Recent ACKnowledgment) — RFC 8985
RACK uses time-based loss detection instead of counting duplicate ACKs:

Advantages over dup-ACK counting:
- Works with SACK and non-SACK
- Not confused by reordering
- Not limited by the “3 dup ACK” threshold
- Better for connections with small windows (fewer than 4 packets in flight)
11.7 TCP_NOTSENT_LOWAT
Controls how much unsent data can be buffered in the kernel socket buffer. This is crucial for latency-sensitive applications (e.g., video streaming, gaming):
int val = 16384; // 16 KB
setsockopt(fd, IPPROTO_TCP, TCP_NOTSENT_LOWAT, &val, sizeof(val));When the unsent data drops below this threshold, epoll/select reports the socket as writable, allowing the application to generate fresh data instead of buffering stale data.
12. Security Considerations
12.1 SYN Flood Attack
Attack: Attacker sends massive numbers of SYN packets with spoofed source IPs. The server allocates resources for each half-open connection, exhausting memory/CPU.
Mitigations:
- SYN cookies (eliminate server-side state for half-open connections)
- SYN proxies (middlebox completes handshake before forwarding)
- Rate limiting SYN packets
- Increasing backlog size
- Firewalls with SYN flood protection
12.2 TCP Reset Attack
Attack: Attacker injects RST segments with guessed sequence numbers to terminate connections.
Mitigations:
- RFC 5961: RST must have sequence number exactly equal to
RCV.NXTto be accepted immediately; otherwise, a “challenge ACK” is sent. - Randomized ISNs
- TCP-AO (Authentication Option)
- IPsec
12.3 TCP Hijacking / Injection
Attack: Attacker injects data into an established connection by guessing sequence and acknowledgment numbers.
Mitigations:
- Randomized ISNs
- Encrypted transport (TLS)
- TCP-AO (RFC 5925) — cryptographic authentication of segments
- IPsec (AH or ESP)
12.4 TCP-AO (Authentication Option) — RFC 5925
Replaces the older TCP MD5 Signature Option (RFC 2385, used heavily for BGP):
- Uses HMAC with configurable algorithms
- Supports key rollover
- Provides per-segment integrity and authentication
12.5 Side-Channel Attacks
- CVE-2016-5696: Linux vulnerability where the global
challenge_ack_limitrate limiter could be used as a side channel to infer sequence numbers of connections between two other hosts (off-path attack). - Mitigations: Randomized challenge ACK limits, noise injection.
12.6 TCP and Firewalls / NATs
TCP’s stateful nature means firewalls and NATs maintain connection tracking tables:

Issues:
- NAT timeout can silently drop idle connections (TCP keepalive helps)
- Stateful firewalls can be overwhelmed by many connections
- Middlebox interference with TCP options (window scale, timestamps, SACK, TFO)
- MPTCP designed to be middlebox-friendly (falls back gracefully)
13. TCP vs. Other Transport Protocols
TCP vs. UDP
| Feature | TCP | UDP |
|---|---|---|
| Connection | Connection-oriented | Connectionless |
| Reliability | Guaranteed delivery | Best effort |
| Ordering | Ordered | Unordered |
| Flow control | Yes (sliding window) | No |
| Congestion control | Yes | No |
| Head-of-line blocking | Yes (in-order delivery) | No |
| Header size | 20–60 bytes | 8 bytes |
| Use cases | HTTP, SMTP, SSH, FTP | DNS, VoIP, gaming, video streaming |
TCP vs. SCTP (Stream Control Transmission Protocol)
| Feature | TCP | SCTP |
|---|---|---|
| Streams | Single byte stream | Multiple independent streams |
| HOL blocking | Yes | No (per-stream ordering) |
| Multi-homing | No | Yes (multiple IP addresses per endpoint) |
| Message boundaries | No (byte stream) | Yes (message-oriented) |
| Connection setup | 3-way handshake | 4-way handshake (with cookie for anti-DoS) |
| Adoption | Universal | Limited (WebRTC data channels, telecom) |
TCP vs. QUIC
QUIC (RFC 9000) was designed to fix TCP’s limitations:
| Feature | TCP | QUIC |
|---|---|---|
| Transport | Kernel-space | User-space (over UDP) |
| Encryption | Optional (TLS layered on top) | Mandatory (TLS 1.3 integrated) |
| Connection setup | 1-3 RTTs (TCP + TLS) | 0–1 RTT |
| HOL blocking | Yes | No (independent streams) |
| Connection migration | No (tied to 4-tuple) | Yes (connection ID) |
| Middlebox ossification | Severe | Minimal (encrypted headers) |
| Congestion control | Kernel-managed | Application-managed |
| Loss recovery | Per-connection | Per-stream |
4. Implementation Details (Kernel Perspective)
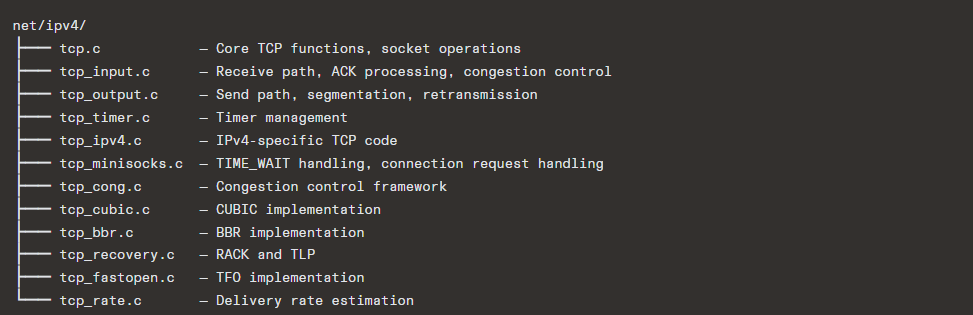
14.1 Linux TCP Implementation
Linux’s TCP implementation is one of the most sophisticated and widely deployed. Key source files:
14.2 Socket Buffers (sk_buff)
The sk_buff (socket buffer) is the fundamental data structure for network packets in Linux:
struct sk_buff {
struct sk_buff *next, *prev; // linked list
struct sock *sk; // owning socket
struct net_device *dev; // network device
unsigned char *head; // start of buffer
unsigned char *data; // start of data
unsigned char *tail; // end of data
unsigned char *end; // end of buffer
unsigned int len; // data length
__u32 priority;
// ... many more fields
unsigned char cb[48]; // control buffer (TCP uses for tcp_skb_cb)
};TCP stores per-segment metadata in the cb field via struct tcp_skb_cb:
struct tcp_skb_cb {
__u32 seq; // Starting sequence number
__u32 end_seq; // SEQ + FIN + SYN + datalen
__u32 tcp_tw_isn; // ISN in TIME_WAIT
struct {
__u16 tcp_gso_segs;
__u16 tcp_gso_size;
};
__u8 tcp_flags; // TCP header flags
__u8 sacked; // SACK/FACK state bits
__u32 ack_seq; // ACK sequence number
// ...
};14.3 TCP Connection Lookup
When a packet arrives, the kernel must find the matching socket. Linux uses a hash table with multiple levels:
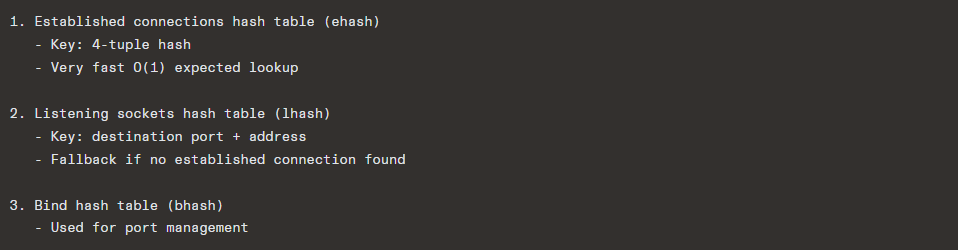
The hash table is RCU-protected for lock-free reads, critical for performance on multi-core systems.
14.4 TCP Memory Management
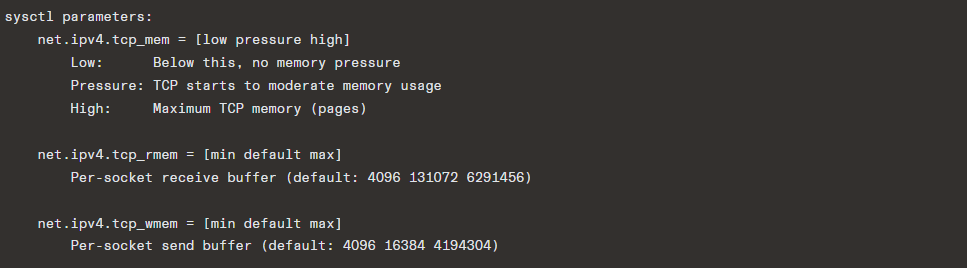
Autotuning: Linux dynamically adjusts socket buffer sizes based on connection characteristics:
- Receive buffer grows up to
tcp_rmem[2]based on observed BDP - Send buffer grows up to
tcp_wmem[2] - Controlled by
tcp_moderate_rcvbuf
14.5 Key Sysctls for TCP Tuning
| Sysctl | Default | Description |
|---|---|---|
tcp_window_scaling | 1 | Enable window scaling |
tcp_sack | 1 | Enable SACK |
tcp_timestamps | 1 | Enable timestamps |
tcp_ecn | 2 | ECN: 0=off, 1=request, 2=accept |
tcp_fastopen | 1 | TFO: bitmask (1=client, 2=server) |
tcp_congestion_control | cubic | Default congestion control |
tcp_slow_start_after_idle | 1 | Reset cwnd after idle period |
tcp_no_metrics_save | 0 | Cache/don’t cache route metrics |
tcp_max_syn_backlog | 128-1024 | SYN queue size |
somaxconn | 4096 | Accept queue size |
tcp_synack_retries | 5 | SYN-ACK retransmissions |
tcp_syn_retries | 6 | SYN retransmissions |
tcp_fin_timeout | 60 | FIN_WAIT_2 timeout (seconds) |
tcp_tw_reuse | 2 | TIME_WAIT reuse for outgoing |
tcp_max_tw_buckets | 262144 | Max TIME_WAIT sockets |
tcp_abort_on_overflow | 0 | RST on accept queue overflow |
tcp_mtu_probing | 0 | PLPMTUD (Path Layer MTU Discovery) |
14.6 Pluggable Congestion Control
Linux allows runtime selection of congestion control algorithms:
# List available algorithms
sysctl net.ipv4.tcp_available_congestion_control
# Set default
sysctl -w net.ipv4.tcp_congestion_control=bbr
# Per-socket (programmatic)
setsockopt(fd, IPPROTO_TCP, TCP_CONGESTION, "bbr", 3);The tcp_congestion_ops structure:
struct tcp_congestion_ops {
void (*init)(struct sock *sk);
void (*release)(struct sock *sk);
u32 (*ssthresh)(struct sock *sk);
void (*cong_avoid)(struct sock *sk, u32 ack, u32 acked);
void (*set_state)(struct sock *sk, u8 new_state);
void (*cwnd_event)(struct sock *sk, enum tcp_ca_event ev);
void (*in_ack_event)(struct sock *sk, u32 flags);
void (*pkts_acked)(struct sock *sk, const struct ack_sample *sample);
u32 (*undo_cwnd)(struct sock *sk);
u32 (*sndbuf_expand)(struct sock *sk);
// ...
};14.7 GRO/GSO Pipeline

GSO (Generic Segmentation Offload): The kernel creates a “super-segment” (up to 64KB). If the NIC supports TSO, it’s segmented in hardware. If not, GSO segments it in software just before transmission — but after routing decisions, keeping the cost of processing per-packet once.
15. Conclusion
TCP is a remarkably sophisticated protocol that has evolved over four decades while maintaining backward compatibility. Its key architectural decisions — reliable byte-stream abstraction, end-to-end principle, multiplicative-decrease congestion control, three-way handshake — have proven remarkably durable.
Key Takeaways
- TCP is a living protocol: From RFC 793 (1981) to RFC 9293 (2022), with continuous evolution via new congestion control algorithms (CUBIC, BBR), loss recovery mechanisms (RACK, TLP, PRR), and extensions (MPTCP, TFO).
- Congestion control is the heart of TCP: The shift from loss-based (Tahoe/Reno) to model-based (BBR) represents a fundamental rethinking, though loss-based algorithms (CUBIC) remain dominant.
- The tension between TCP and modern requirements: TCP’s in-order delivery causes head-of-line blocking. Its kernel-space implementation makes iteration slow. Its header ossification (middlebox interference) limits extensibility. These motivate QUIC.
- TCP still dominates: Despite QUIC’s growth, TCP carries the majority of Internet traffic and will continue to do so for decades given its deep integration into every operating system, network device, and application.
- Tuning matters: Understanding TCP internals — buffer sizing, congestion control selection, option negotiation, timer configuration — is essential for achieving optimal performance in specific environments (data centers, WANs, lossy links).
Further Reading
- RFC 9293 — TCP specification (consolidation of RFC 793 and others)
- RFC 5681 — TCP Congestion Control
- RFC 7323 — TCP Extensions for High Performance
- RFC 8312 — CUBIC
- RFC 8985 — RACK-TLP
- RFC 9000 — QUIC (for comparison)
- “TCP/IP Illustrated, Volume 1” by W. Richard Stevens (updated by Kevin Fall)
- “Computer Networking: A Top-Down Approach” by Kurose & Ross
- Linux kernel source:
net/ipv4/tcp*.c - Neal Cardwell et al., “BBR: Congestion-Based Congestion Control” (ACM Queue, 2016)